Events 2023
InvasIC Seminar, June 07, 2023 at FAU: An Agile and Explainable Exploration of Efficient HW/SW Codesigns of Deep Learning Accelerators Using Bottleneck Analysis
Prof. Aviral Shrivastava (Arizona State University).

Prof. Shrivastava with Prof. Jürgen Teich
Effective design space exploration (DSE) is paramount for hardware/software codesigns of deep learning accelerators that must meet strict execution constraints. For their vast search space, existing DSE techniques can require excessive number of trials to obtain valid and efficient solution because they rely on black-box explorations that do not reason about design inefficiencies. We propose Explainable-DSE – a framework for DSE of DNN accelerator codesigns using bottleneck analysis. By leveraging information about execution costs from bottleneck models, our DSE can identify the bottlenecks and therefore the reasons for design inefficiency and can therefore make mitigating acquisitions in further explorations. We describe the construction of such bottleneck models for DNN accelerator domain. We also propose an API for expressing such domain-specific models and integrating them into the DSE framework. Acquisitions of our DSE framework caters to multiple bottlenecks in executions of workloads like DNNs that contain different functions with diverse execution characteristics. Evaluations for recent computer vision and language models show that Explainable-DSE mostly explores effectual candidates, achieving codesigns of 6× lower latency in 47× fewer iterations vs. non-explainable techniques using evolutionary or ML-based optimizations. By taking minutes or tens of iterations, it enables opportunities for runtime DSEs.
Events 2022
InvasIC Seminar, July 28, 2022 at TUM: The Future of Hardware Technologies for Computing: N3XT 3D MOSAIC, Illusion Scaleup, Co-Design
Prof. Subhasish Mitra (Stanford University).


Prof. Mitra at TUM
The computation demands of 21st-century abundant-data workloads, such as AI / machine learning, far exceed the capabilities of today’s computing systems. For example, a Dream AI Chip would ideally co-locate all memory and compute on a single chip, quickly accessible at low energy. Such Dream Chips aren’t realizable today. Computing systems instead use large off-chip memory and spend enormous time and energy shuttling data back-and-forth. This memory wall gets worse with growing problem sizes, especially as conventional transistor miniaturization gets increasingly difficult. The next leap in computing performance requires the next leap in integration. Just as integrated circuits brought together discrete components, this next level of integration must seamlessly fuse disparate parts of a system – e.g., compute, memory, inter-chip connections – synergistically for large energy and execution time benefits. This talk presented such transformative NanoSystems by exploiting the unique characteristics of emerging nanotechnologies and abundant-data workloads. We created new chip architectures through ultra-dense (e.g., monolithic) 3D integration of logic and memory – the N3XT 3D approach. Multiple N3XT 3D chips were integrated through a continuum of chip stacking/interposer/wafer-level integration — the N3XT 3D MOSAIC. To scale with growing problem sizes, new Illusion systems orchestrate workload execution on N3XT 3D MOSAIC creating an illusion of a Dream Chip with near-Dream energy and throughput. Beyond existing cloud-based training, we demonstrated the first non-volatile chips for accurate edge AI training (and inference) through new incremental training algorithms that are aware of underlying non-volatile memory technology constraints. Several hardware prototypes, built in industrial and research fabrication facilities, demonstrate the effectiveness of our approach. We targeted 1,000X system-level energy-delay-product benefits, especially for abundant-data workloads. We also addressed new ways of ensuring robust system operation despite growing challenges of design bugs, manufacturing defects, reliability failures, and security attacks.
InvasIC Seminar, July 7, 2022 at TUM: A Principled Approach for Accelerating AI Systems Innovations
Dr. Jinjun Xiong (University at Buffalo)


Dr. Jinjun Xiong at TUM
AI has become an increasingly powerful technology force that will transform different aspects of our society, such as transportation, healthcare, education, and scientific discovery. But the diverse layers of software abstractions, hardware heterogeneity, privacy and security concerns, and big-data driven machine learning models have made the development of optimized AI solutions extremely challenging. This talk discussed some of my related research efforts in the past decade on developing enterprise-scale high performance AI solutions and innovating related AI systems technologies, in particular, a data-driven reviewer recommendation AI solution, automation tools to identify system performance bottlenecks, and innovative software-hardware co-optimization algorithms for accelerating AI algorithms. I contextualized these efforts in my efforts of developing a principled approach for accelerating AI systems innovations. I also discussed a couple of other related AI research, for example, one on developing statistical neural networks inspired by my early work on statistical timing analysis, and one on developing a novel neural architecture search work.
InvasIC Seminar, May 27, 2022 at FAU: The FABulous Open Source eFPGA Framework
Prof. Dr. Dirk Koch (Universität Heidelberg)
This talk introduced the FABulous open source eFPGA framework, which was used in the design of multiple chips. FABulous deals with all the modeling, fabric synthesis, ASIC implementation, and simulation/emulation aspects, as well as the compilation of user bitstreams that will ultimately run on the generated fabrics. For this, FABulous is integrating several other open source tools, including Yosis, nextpnr, OpenRoad, and the Verilator. The talk also discussed some of the FPGA engineering challenges and present some of the recent chips, including an open-everything chip and a ReRAM (memristor) FPGA test chip.
InvasIC Seminar, May 20, 2022 at FAU: A RISC-V Experience Report
Prof. Dr. Michael Engel (Universität Bamberg)
The RISC-V architecture is one of the promising foundations for current and upcoming research projects as well as commercial products. It is especially attractive due to its open instruction-set architecture, which allows to create compliant implementations without having to license the use of specifications or IP implementations from a processor designer. In recent years, a whole ecosystem of open as well as commercial hardware and software solutions based on RISC-V has originated, with the vision of being able to create a completely open source computer system - from the first bit of hardware (description) to the last bit of software. After an overview of the RISC-V architecture and available components, in this talk, I discussed aspects of the RISC-V architecture and specifically its hardware/software interface relevant for system software. Based on previous projects to port system-level code together with my students, I analyzed intricacies of the interface RISC-V provides to system software as well as the different relevant instruction set extensions available and in development. Finally, I gave a glimpse on ongoing research in my group at Bamberg University and at NTNU which uses RISC-V to investigate novel approaches to hardware/software interfacing for systems with persistent main memory as well as distributed operating system environments for IoT applications.

Prof. Dr.-Ing. Jürgen Teich and Prof. Dr.-Ing Michael Engel
InvasIC Seminar, February 3, 2022, Virtual Talk: Hardware/Software Co-Design of Deep Learning Accelerators
Prof. Dr. Yiyu Shi (University of Notre Dame, USA)
The prevalence of deep neural networks today is supported by a variety of powerful hardware platforms including GPUs, FPGAs, and ASICs. A fundamental question lies in almost every implementation of deep neural networks: given a specific task, what is the optimal neural architecture and the tailor-made hardware in terms of accuracy and efficiency? Earlier approaches attempted to address this question through hardware-aware neural architecture search (NAS), where features of a fixed hardware design are taken into consideration when designing neural architectures. However, we believe that the best practice is through the simultaneous design of the neural architecture and the hardware to identify the best pairs that maximize both test accuracy and hardware efficiency. In this talk, we presented novel co-exploration frameworks for neural architecture and various hardware platforms including FPGA, NoC, ASIC and Computing-in-Memory, all of which are the first in the literature. We demonstrated that our co-exploration concept greatly opens up the design freedom and pushes forward the Pareto frontier between hardware efficiency and test accuracy for better design tradeoffs.

Prof. Dr.-Ing. Ulf Schlichtmann and Prof. Dr. Yihu Shi.
Events 2021
InvasIC Seminar, July 16, 2021, Virtual Talk: Hardware-Software Contracts for Safe and Secure Systems
Univ.-Prof. Dr. Jan Reineke (Universität des Saarlandes)
Trains, planes, and other safety- and security-critical systems that modern society relies on are controlled by computer systems, as is much of our critical infrastructure, including the power grid and cellular networks. But can we trust in the safety and security of these systems?
I argued that today's hardware-software abstractions, instruction set architectures (ISAs), are fundamentally inadequate for the development of safe or secure systems. Indeed, ISAs abstract from timing, making it impossible to develop safety-critical systems that have to satisfy real-time constraints on top of them. Neither do ISAs provide sufficient security guarantees, making it impossible to develop secure systems on top of them. As a consequence, engineers are forced to rely on brittle timing and security models that are proven wrong time and again, as evidenced e.g. by the recent Spectre attacks; putting our society at risk.
I proposed to tackle this problem at its root by introducing novel hardware-software contracts that extend the guarantees provided by ISAs to capture key non-functional properties. These hardware-software contracts will formally capture the expectations on correct hardware implementations and will lay the foundation for achieving safety and security guarantees as the software level. This will enable the systematic engineering of safe and secure hardware-software systems we can trust in.
InvasIC Seminar, June 11, 2021, Virtual Talk: Advancing Coarse-Grained Reconfigurable Array (CGRA) with Compiler/Architecture Co-design
Professor Tulika Mitra (National University of Singapore)

Prof. Dr.-Ing. Jürgen Teich and Prof. Dr. Tulika Mitra.
The Internet of Things (IoT) system architectures are rapidly moving towards edge computing where computational intelligence is embedded in the edge devices at or near the sensors instead of the remote cloud for time-sensitivity, security, privacy, and connectivity reasons. At present, the limited computing capability of power, area constrained edge devices severely restricts their potential. In this talk, I will present ultra-low power, Coarse-Grained Reconfigurable Array (CGRA) accelerators as a promising approach to offer close to fixed-functionality ASIC-like energy efficiency while supporting diverse applications through full compile-time configurability. The central challenge is efficient spatio-temporal mapping of the application expressed in high-level programming languages with complex control flow and memory accesses to a concrete CGRA accelerator by respecting its constraints. We approach this challenge through a synergistic hardware-software co-designed approach with (a) innovations at the accelerator architecture level to improve the efficiency of the application execution as well as ease the burden on compilation, and (b) innovations at the compiler level to fully exploit the architectural optimizations for efficient and fast mapping on the accelerator.
InvasIC Seminar, June 8, 2021, Virtual Talk: Adversarial Machine Learning in the Audio Domain
Professor Dr. Thorsten Holz (Ruhr-Universität)
The advent of Deep Learning has transformed our digital society. Starting with simple recommendation techniques or image recognition applications, machine-learning systems have evolved to play games at eye level with humans, identify faces, or recognize speech at the level of human listeners. These systems are now virtually ubiquitous, gaining access to critical and sensitive areas of our daily lives. On the downside, such algorithms are brittle and vulnerable to malicious input, so-called adversarial examples. In these evasion attacks, a targeted input is perturbed by imperceptible amounts of noise to trigger misclassification of the victim's neural network. In this talk, we provided an overview of some recent results in this area, with a focus on adversarial attacks against automatic speech recognition systems. Furthermore, we also sketched challenges for detecting deep fake images and similar kinds of artificially generated media.
InvasIC Seminar, May 14, 2021, Virtual Talk: Full-Stack Optimizations for Next-Generation Deep-Learning Accelerators
Professor Yakun Sophia Shao (University of California, Berkeley)
Machine learning is poised to substantially change society in the next 100 years, just as how electricity transformed the way industries functioned in the past century. In particular, deep learning has been adopted across a wide variety of industries, from computer vision, natural language processing, autonomous driving, to robotic manipulation. Motivated by the high computational requirement of deep learning, there has been a large number of novel deep-learning accelerators proposed in academia and industry to meet the performance and efficiency demands of deep-learning applications. In this talk, I provided an overview of challenges and opportunities for domain-specific architectures for deep learning. In particular, I discussed some of our recent efforts in building efficient deep-learning accelerators through full-stack optimizations at circuits, architecture, and compiler levels.
InvasIC Seminar, April 20, 2021, Virtual Talk: In Hardware We Trust? From TPMs to Enclave Computing on RISC-V
Professor Dr. Ahmad Sadeghi (TU Darmstadt)
The large attack surface of commodity operating systems has motivated academia and industry to develop novel security architectures that provide strong hardware-assisted protection for sensitive applications using the so-called enclaves. However, deployed enclave architectures often lack important security features, and assume threat models which do not cover cross-layer attacks, such as microarchitectural exploits and beyond. Thus, recent academic research has proposed a new line of enclave architectures with distinct features and more comprehensive threat models, many of which were developed on the open RISC-V architecture.
In this talk, we presented a brief overview of the Trusted Computing Landscape, its promises and pitfalls. We discussed selected RISC-V based enclave architectures recently proposed, discussed their features, limitations and open challenges which we aim to tackle in our current research using our security architecture CURE. Finally, we shortly reported on the insights we gained on cross-layers attacks in the world’s largest hardware security competitions franchise that we have been organizing with Intel and Texas AMU since 2018.
InvasIC Seminar, March 25, 2021, Virtual Talk: Cyber-Physical Systems Security: A Pacemaker Case Study
Partha Roop (University of Auckland)
Cyber-Physical attacks (CP attacks), originating in cyber space but damaging physical infrastructure, are a significant recent research focus. Such attacks have affected many Cyber-Physical Systems (CPSs) such as smart grids, intelligent transportation systems and medical devices. In this talk we considered techniques for the detection and mitigation of CP attacks on medical devices. It is obvious that such attacks have immense safety implication. Our work is based on formal methods, a class of mathematically founded techniques for the specification and verification of safety-critical systems. A cardiac pacemaker was our motivating medical device and we described its interaction with the heart. We then provided an overview of formal methods with particular emphasis on run-time based approaches, which are ideal for the design of security monitors. Subsequently, we discussed in detail two recent approaches developed in our group for attack detection and mitigation. We thus provided an overview of run-time based formal approaches for attack detection and mitigation of medical devices.
Events 2020
InvasIC Seminar, December 18, 2020, Virtual Talk: Sustained Performance Scaling in the Light of Bounded Growth and Technology Constraints
Prof. Holger Fröning (Universität Heidelberg)
The end of Moore's law has been predicted for many years, in combinations with statements about exaggerations of its end. However, we are currently observing a phase of substantial slow-down in key metrics associated with silicon device manufacturing, and, as a result, huge issues with sustained performance scaling. In this talk, we reviewed the most important recent and current trends in computer architecture, in particular in the light of diminishing returns from feature size scaling and power constraints of CMOS technology. Ultimately, we see that energy efficiency is and will be key for a continuous performance scaling, however in substantially different flavors. In this context, particular attention will be put on predictive models for performance and power, as well as a short review of our efforts in the context of the DeepChip project, and how both can help from a system's perspective for continued performance scaling.
InvasIC Seminar, December 11, 2020, Virtual Talk: Design of Low Power Hearing Aid Processors
Prof. Holger Blume (Leibniz Universität Hannover)
Processors for hearing aids are highly specialized for audio processing and they have to meet challenging hardware restrictions. This talk aims to provide an overview of the requirements, architectures and implementations of these processors. Special attention is paid to the increasingly important class of application specific instruction-set processors. The main focus of this talk lies on hardware-related aspects such as the processor architecture, the interfaces, the application-specific integrated circuit technology, and the operating conditions. The different hearing aid implementations are compared in terms of power consumption, silicon area, and computing performance for the algorithms used. Challenges for the design of future hearing aid processors being able to process AI-based hearing aid algorithms and EEG-enhanced hearing aid algorithms are discussed based on current trends and developments.

InvasIC Seminar, November 20, 2020, Virtual Talk: Journey from Mobile Platforms to Self-Powered Wearable Systems
Prof. Umit Ogras (Arizona State University, USA)
We experience a major shift in the form factor of electronic systems every 10 to 15 years. The most recent examples are the mobile platforms powered by heterogeneous system-on-chips (SoCs), while the next one is yet to dominate the market. Despite their impressive performance, mobile platforms still suffer from tight thermal constraints and resulting power consumption limitations. Furthermore, the complexity of current designs surpasses our ability to optimally control the power management knobs, such as the number, type and frequencies of active cores. The first part of this talk overviewed a few recent results on the modeling, analysis and optimization of power-temperature dynamics of multiprocessor SoCs. The accuracy and effectiveness of these approaches were demonstrated on commercial ARM and x86 (Atom) SoCs. In the second part, we overviewed “Systems-on-Polymer” as a candidate technology to drive the next wave of computing. This approach has recently been introduced to combine the advantages of flexible and traditional silicon technologies. Within this context, we presented a flexibility-aware design methodology, and a self-powered flexible prototype for wearable health monitoring.


Prof. Umit Ogras (Arizona State University, USA) spoke at the InvasIC Seminar.
InvasIC Seminar, January 7, 2020 at FAU: Code is Ethics — Formal Techniques for a Better World
Prof. Rolf Drechsler (University of Bremen/DFKI)

Prof. Dr.-Ing. Jürgen Teich, Prof. Drechsler and Prof. Dr. Oliver Keszöcze (from left).
Computers are involved in our every-day life, making increasingly consequential decisions. This raises the question of the ethics of these decisions, for example when autonomous cars are concerned. We argue that the ethics of the decisions taken by a computer are in fact those of the developers, encoded in the program ("code is ethics"). This encoding is mostly implicit — programmers and users are often even not aware of the implicit decisions that are being made before the program is even run. We suggest that formal methods are an excellent way to make the criteria under which these decisions are taken explicit, because formal specifications are more concise, abstract and clearer than code. This way, it becomes clear why systems act the way they do, and where the responsibility for their behaviour lies.
Events 2019
InvasIC Seminar, November 29, 2019 at FAU: Scalable Data Management on Modern Networks
Prof. Carsten Binnig (TU Darmstadt)

Prof. Carsten Binnig, Prof. Dr.-Ing. Jürgen Teich, Andreas Becher, Prof. Meyer-Wegener (from left).
As data processing evolves towards large scale, distributed platforms, the network will necessarily play a substantial role in achieving efficiency and performance. Modern high-speed networks such as InfiniBand, RoCE, or Omni-Path provide advanced features such as Remote-Direct-Memory-Access (RDMA) that have shown to improve the performance and scalability of distributed data processing systems. Furthermore, switches and network cards are becoming more flexible while programmability at all levels (aka, software-defined networks) opens up many possibilities to tailor the network to data processing applications and to push processing down to the network elements. In this talk, I discussed opportunities and presented our recent research results to redesign scalable data management systems for the capabilities of modern networks.
InvasIC Seminar, September 27, 2019 at FAU: Design of Decentralized Embedded IoT Systems
Prof. Sebastian Steinhorst (TUM)
With the Internet of Things (IoT), technological advancements in the area of digitalization are introduced in almost all sectors of industry and society. IoT system architectures are traditionally designed in a hierarchical and centralized fashion, which, however, can no longer keep up with the increasing requirements of scalability, manageability, efficiency and security of the vast amount of emerging applications. Hence, decentralization might be the only possibility to meet the requirements imposed on future IoT systems, eventually driving architecture design towards self-organizing systems. However, in system architectures composed of resource-constrained embedded IoT devices, existing decentralization methodologies significantly exceed the computational and communication capabilities of such devices. Therefore, this talk illustrated our progress in developing design methods and algorithms that contribute to efficient decentralization of embedded IoT devices in system architectures. The talk discussed how consensus efficiency can be improved in different application scenarios such as autonomous driving and Industry 4.0. For the latter, we are also targeting the challenge of interoperability and self-organization in decentralized industrial IoT architectures. In this context, our recent advancements to describe the capabilities of IoT devices in a semantically strong form such that devices will be able to interoperate and coordinate themselves by exchanging their capabilities were presented. Eventually, such devices will be enabled to collaborate autonomously in order to perform system-level functionality.
InvasIC Seminar, July 19, 2019 at FAU: Approximate Computing: Design & Test for Integrated Circuits
Prof. Alberto Bosio (Ecole Centrale de Lyon, France)

Prof. Alberto Bosio (on the right) and Prof. Dr.-Ing. Jürgen Teich (left).
Todays’ Integrated Circuits (ICs) are starting to reach the physical limits of CMOS technology. Among the multiple challenges, we can mention high leakage current (i.e., high static power consumption), reduced performance gain, reduced reliability, complex manufacturing processes leading to low yield and complex testing procedures, and extremely costly masks. In other words, ICs manufactured with the latest technology nodes are less and less efficient (w.r.t. both performance and energy consumption) than forecasted by the Moore's law. Moreover, manufactured devices are becoming less and less reliable, meaning that errors can appear during the normal lifetime of a device with a higher probability than with previous technology nodes. Fault tolerant mechanisms are therefore required to ensure the correct behavior of such devices at the cost of extra area, power and timing overheads. Finally, process variations force engineers to add extra guard bands (e.g., higher supply voltage or lower clock frequency than required under normal circumstances) to guarantee the correct functioning of manufactured devices.
In the recent years, the Approximate Computing (AxC) paradigm has emerged. AxC is based on the intuitive observation that, while performing exact computation requires a high amount of resources, allowing selective approximation or occasional violation of the specification can provide gains in efficiency (i.e., less power consumption, less area, higher manufacturing yield) without significantly affecting the output quality. This talk first discussed the basic concepts of the AxC paradigm and then focused on the Design & Test of Integrated Circuits for AxC-based systems. From the design point of view, a methodology able to automatically explore the impact of different approximation techniques on a given input algorithm was presented. The methodology consists is a design exploration tool able to find approximate versions for an algorithm described in software (i.e., coded in C/C++), by mutating the original code. The mutated (i.e., approximated) version of the algorithm is then synthetized by using a High-Level Synthesis tool to obtain a HDL code. The latter is finally mapped into an FPGA to estimate the benefits of the approximation in terms of area reduction and performances. Regarding the test of integrated circuits, we start from the consideration that AxC-based systems can intrinsically accept the presence of faulty hardware (i.e., hardware that can produce errors). This paradigm is also called "computing on unreliable hardware". The hardware-induced errors have to be analyzed to determine their propagation through the system layers and eventually determining their impact on the final application. In other words, an AxC-based system does not need to be built using defect-free ICs. Indeed, AxC-based systems can manage at higher-level the errors due to defectives ICs, or those errors simply do not significantly impact the final applications. Under this assumption, we can relax test and reliability constraints of the manufactured ICs. One of the ways to achieve this goal is to test only for a subset of faults instead of targeting all possible faults. In this way, we can reduce the manufacturing cost since we eventually reduce the number of test patterns and thus the test time.
InvasIC Seminar, May 17, 2019 at FAU: Optimizing Enterprise Servers across the Hardware and Software Stack
Dr. Silvia Melitta Mueller (IBM, Germany)
 Enterprise servers are used for a wide range of business applications,
spanning from traditional banking, accounting, and insurance applications
to emerging workloads around Blockchain, security, and AI. All these
applications have a few aspects in common: they are compute intensive,
mission critical, and clients expect better performance and power
performance from one generation to the next. This can best be achieved by
co-optimizing hardware, compiler, and application.
Enterprise servers are used for a wide range of business applications,
spanning from traditional banking, accounting, and insurance applications
to emerging workloads around Blockchain, security, and AI. All these
applications have a few aspects in common: they are compute intensive,
mission critical, and clients expect better performance and power
performance from one generation to the next. This can best be achieved by
co-optimizing hardware, compiler, and application.
A big difference between traditional and emerging applications is the degree of freedom for this optimization. Emerging workloads attack new frontiers and have the freedom of first of a kind designs; being able to invent new data formats, system structures and algorithms. For traditional workloads, on the other hand, the systems got optimized over several decades, and it is hard to find still big enhancements.
The talk showed how IBM optimizes its systems based on two extreme: (1) pushing the frontiers of Deep Learning / AI with ultra-low-precision arithmetic (2) speeding up banking applications by optimized arithmetic
InvasIC Seminar, May 17, 2019 at TUM: On the road to Self-Driving IC Design Tools and Flows
Prof. Andrew B. Kahng (UC San Diego)
 At today’s leading edge, critical scaling levers for semiconductor product companies include design cost, quality, and schedule. To reduce time and effort in IC implementation, fundamental challenges must be solved. First, the need for
(expensive) humans must be removed wherever possible. Humans are skilled at predicting downstream flow failures, evaluating key early decisions such as RTL floorplanning, and deciding tool/flow options to apply to a given design.
Achieving human-quality prediction, evaluation and decision-making will require new machine learning-centric models across designs, optimization heuristics, and EDA tools/flows. Second, to reduce design schedule, focus must return to the
long-held dream of single-pass design.
Future design tools and flows that never require iteration and never fail (but, without undue conservatism) demand new paradigms and core algorithms for parallel search in design automation. Third, learning-based models of tools and flows
must continually improve with additional design experiences. Therefore, the EDA and design ecosystem must deploy new infrastructure for machine learning model development and sharing.
At today’s leading edge, critical scaling levers for semiconductor product companies include design cost, quality, and schedule. To reduce time and effort in IC implementation, fundamental challenges must be solved. First, the need for
(expensive) humans must be removed wherever possible. Humans are skilled at predicting downstream flow failures, evaluating key early decisions such as RTL floorplanning, and deciding tool/flow options to apply to a given design.
Achieving human-quality prediction, evaluation and decision-making will require new machine learning-centric models across designs, optimization heuristics, and EDA tools/flows. Second, to reduce design schedule, focus must return to the
long-held dream of single-pass design.
Future design tools and flows that never require iteration and never fail (but, without undue conservatism) demand new paradigms and core algorithms for parallel search in design automation. Third, learning-based models of tools and flows
must continually improve with additional design experiences. Therefore, the EDA and design ecosystem must deploy new infrastructure for machine learning model development and sharing.
At UCSD, a recently launched U.S. DARPA project, OpenROAD (“Foundations and Realization of Open, Accessible Design”), seeks to develop electronic chip design automation tools for 24-hour, “no-human-in-the-loop” hardware layout generation. The project aims to combine several new approaches in chip design — machine learning and parallel optimization, along with "extreme partitioning" of the design problem — to develop a fast, autonomous design process. Today’s talk will sketch a few waypoints "on the road to self-driving IC design tools and flows", framed as opportunities for collaborations that span machine learning, IC design, EDA and academia.
Events 2018
InvasIC Seminar, November 16, 2018 at TUM: Algebraic Statistical Static Timing
Dr. Sani Nassif (Radyalis, USA)
 One of the techniques for understanding the impact of process variability on digital circuit robustness and performance is statistical static timing analysis. Early in its development,
SSTA was expressed in terms of paths through the circuit, but later research has been focused on block-based analysis. This talk revisits this topic framed in reference to analysis accuracy and
overall performance. We show that a path-based approach lends itself well to more accurate models as well as a high-performance implementation based on high performance BLAS libraries.
Invitation
One of the techniques for understanding the impact of process variability on digital circuit robustness and performance is statistical static timing analysis. Early in its development,
SSTA was expressed in terms of paths through the circuit, but later research has been focused on block-based analysis. This talk revisits this topic framed in reference to analysis accuracy and
overall performance. We show that a path-based approach lends itself well to more accurate models as well as a high-performance implementation based on high performance BLAS libraries.
Invitation
InvasIC Seminar, September 20, 2018 at TUM: Comparing Voltage Adaptation Performance between Replica and In-Situ Timing Monitors
Prof. Masanori Hashimoto (Osaka University, Japan)

 Adaptive voltage scaling (AVS) is a promising approach to over- come manufacturing variability, dynamic environmental fluctuation, and aging. This talk focused on timing sensors necessary
for AVS implementation and compares in-situ timing error predictive FF (TEP-FF) and critical path replica in terms of how much volt- age margin can be reduced. For estimating the theoretical
bound of ideal AVS, this work proposes linear programming based minimum supply voltage analysis and discusses the voltage adaptation performance quantitatively by investigating the gap between
the lower bound and actual supply voltages. Experimental results show that TEP-FF based AVS and replica based AVS achieve up to 13.3% and 8.9% supply voltage reduction, respectively while satisfying
the target MTTF. AVS with TEP-FF tracks the theoretical bound with 2.5 to 5.6 % voltage margin while AVS with replica needs 7.2 to 9.9 % margin.
Invitation
Adaptive voltage scaling (AVS) is a promising approach to over- come manufacturing variability, dynamic environmental fluctuation, and aging. This talk focused on timing sensors necessary
for AVS implementation and compares in-situ timing error predictive FF (TEP-FF) and critical path replica in terms of how much volt- age margin can be reduced. For estimating the theoretical
bound of ideal AVS, this work proposes linear programming based minimum supply voltage analysis and discusses the voltage adaptation performance quantitatively by investigating the gap between
the lower bound and actual supply voltages. Experimental results show that TEP-FF based AVS and replica based AVS achieve up to 13.3% and 8.9% supply voltage reduction, respectively while satisfying
the target MTTF. AVS with TEP-FF tracks the theoretical bound with 2.5 to 5.6 % voltage margin while AVS with replica needs 7.2 to 9.9 % margin.
Invitation
InvasIC Seminar, August 31, 2018 at TUM: Routability Prediction in Early Placement Stages using Convolution Neural Networks
Assoc. Prof. Shao-Yun Fang (National Taiwan University of Science and Technology)
 With the dramatic shrinking of feature size and the advance of semiconductor technology nodes, numerous and complicated design rules need to be followed, and a chip design can only be taped-out
after passing design rule check (DRC). The high design complexity seriously deteriorates design routability, which can be measured by the number of DRC violations (DRVs) after the detailed routing
stage. Early routability prediction helps designers and tools perform preventive measures so that DRVs can be avoided in a proactive manner. Thanks to the great advance of multi-core systems, machine
learning has many amazing advances in the recent years. In this talk, research methodologies leveraging convolutional neural network (CNN) for DRV prediction in both the macro placement and cell
placement stages will be introduced.
Invitation
With the dramatic shrinking of feature size and the advance of semiconductor technology nodes, numerous and complicated design rules need to be followed, and a chip design can only be taped-out
after passing design rule check (DRC). The high design complexity seriously deteriorates design routability, which can be measured by the number of DRC violations (DRVs) after the detailed routing
stage. Early routability prediction helps designers and tools perform preventive measures so that DRVs can be avoided in a proactive manner. Thanks to the great advance of multi-core systems, machine
learning has many amazing advances in the recent years. In this talk, research methodologies leveraging convolutional neural network (CNN) for DRV prediction in both the macro placement and cell
placement stages will be introduced.
Invitation
InvasIC Seminar, July 17, 2018 at FAU: Designing Static and Dynamic Software Systems - A SystemJ Perspective
Prof. Zoran Salcic (The University of Auckland, New Zealand)
 Embedded and cyber-physical systems involve hardware and software design and are becoming increasingly software-centric. Traditional programming languages such as C/C++ and Java have
been used as the primary languages in designing these systems, where programming has been typically extended with run-time concepts that allow designers to employ concurrency (e.g. by
using real-time operating systems or other types of run-time support). This led to plethora of techniques to structure and run those systems and satisfy various functional and other
requirements. However, structuring of software underpinned by formal, mathematical models, remained on a side-track.
In this talk we presented an approach to software systems design underpinned with a formal model of computation (MoC), in our case Globally Asynchronous Locally Synchronous
(GALS), which naturally models huge number of embedded and cyber-physical systems, as well as emerging software systems that execute on distributed (networked) platforms. Based on GALS
MoC as the central theme, we developed a system-level programming language SystemJ that allows designers to design concurrent GALS software systems in a seamless way. Moreover, the
approach still preserves benefits of using a standard programming language, Java in SystemJ case. Originally aimed at the design of static concurrent programs/systems, the approach has
been extended in two major directions, (1) (hard) real-time systems when time-predictable execution platforms are used and (2) dynamic, reconfigurable software systems, where the number
of concurrent software behaviours varies over time of system operation.
Embedded and cyber-physical systems involve hardware and software design and are becoming increasingly software-centric. Traditional programming languages such as C/C++ and Java have
been used as the primary languages in designing these systems, where programming has been typically extended with run-time concepts that allow designers to employ concurrency (e.g. by
using real-time operating systems or other types of run-time support). This led to plethora of techniques to structure and run those systems and satisfy various functional and other
requirements. However, structuring of software underpinned by formal, mathematical models, remained on a side-track.
In this talk we presented an approach to software systems design underpinned with a formal model of computation (MoC), in our case Globally Asynchronous Locally Synchronous
(GALS), which naturally models huge number of embedded and cyber-physical systems, as well as emerging software systems that execute on distributed (networked) platforms. Based on GALS
MoC as the central theme, we developed a system-level programming language SystemJ that allows designers to design concurrent GALS software systems in a seamless way. Moreover, the
approach still preserves benefits of using a standard programming language, Java in SystemJ case. Originally aimed at the design of static concurrent programs/systems, the approach has
been extended in two major directions, (1) (hard) real-time systems when time-predictable execution platforms are used and (2) dynamic, reconfigurable software systems, where the number
of concurrent software behaviours varies over time of system operation.
InvasIC Seminar, July 17, 2018 at TUM: Memristive Electronics
Prof. Sung-Mo (Steve) Kang (Jack Baskin School of Engineering, UC Santa Cruz)
The amount of data increased in the last two years alone accounts for ten percent of the total data available today. The sensing and acquisition, storage, and analysis of data are continually posing great challenges. The recent phenomenal advancement of artificial intelligence (AI) based on machine learning (ML) has found significant applications in many fields such as autonomous vehicle, medicine, and manufacturing. Machine learning and thus artificial intelligence can benefit from neuromorphic circuits and systems that are biologically-inspired. In this talk we highlighted the hardware-software synergy, memristor-based electronics and applications for storage and emulation of neuronal behaviors, synaptic interconnects, and neuromorphic computing. Historical perspective including Moore’s law, More than Moores, the current state-of-the-art in nanoelectronics, and future challenges in the era of the fourth industrial revolution were also discussed.
InvasIC Seminar, July 12, 2018 at FAU: Interference analysis with models for multi-core platform, AURIX TC27x - the case study
Wei-Tsun Sun PhD (IRT Antoine de Saint Exupéry)

Interferences between cores have to be taken into account when performing timing analysis for multi-copre platforms. This talk presents an approach to carry out interference analysis from available data-sheet(s) of a given platform. A description model is firstly captured from the data-sheet, and then is translated to AADL model. The AADL model is then transform to Prolog predicates. STRANGE, a tool written in Prolog is used to extract structural information from the predicates, and is also able to detect all potential interferences. We use AURIX TC27x as the show-case in this document to demonstrate how the proposed methodology can be applied, which enables the possibilities of being adapted for the other architectures.
InvasIC Seminar, July 5, 2018 at FAU: AnyDSL: A Partial Evaluation Framework for Programming High-Performance Libraries
Prof. Sebastian Hack (Universität des Saarlandes)
 Writing performance-critical software productively is still a challenging task because performance usually conflicts genericity. Genericity makes programmers productive as it
allows them to separate their software into components that can be exchanged and reused independently from each other. To achieve performance however, it is mandatory to instantiate
the code with algorithmic variants and parameters that stem from the application domain, and tailor the code towards the target architecture. This requires pervasive changes to the
code that destroy genericity.
In this talk, I advocated programming high-performance code using partial evaluation and present AnyDSL, a clean-slate programming system with a simple, annotation-based, online
partial evaluator. I showed that AnyDSL can be used to productively implement high-performance codes from various different domains in a generic way map them to different target
architectures (CPUs with SIMD units, GPUs). Thereby, the code generated using AnyDSL achieves performance that is in the range of multi man-year, industry-grade, manually-optimized
expert codes and highy-optimized code generated from domains specific languages.
Writing performance-critical software productively is still a challenging task because performance usually conflicts genericity. Genericity makes programmers productive as it
allows them to separate their software into components that can be exchanged and reused independently from each other. To achieve performance however, it is mandatory to instantiate
the code with algorithmic variants and parameters that stem from the application domain, and tailor the code towards the target architecture. This requires pervasive changes to the
code that destroy genericity.
In this talk, I advocated programming high-performance code using partial evaluation and present AnyDSL, a clean-slate programming system with a simple, annotation-based, online
partial evaluator. I showed that AnyDSL can be used to productively implement high-performance codes from various different domains in a generic way map them to different target
architectures (CPUs with SIMD units, GPUs). Thereby, the code generated using AnyDSL achieves performance that is in the range of multi man-year, industry-grade, manually-optimized
expert codes and highy-optimized code generated from domains specific languages.
InvasIC Seminar, June 15, 2018 at FAU: Cross Media File Storage with Strata
Prof. Simon Peter (The University of Texas at Austin, USA)
Current hardware and application storage trends put immense pressure on the operating system's storage subsystem. On the hardware side, the market for storage devices has diversified to a multi-layer storage topology spanning multiple orders of magnitude in cost and performance. Applications increasingly need to process small, random IO on vast data sets with low latency, high throughput, and simple crash consistency. File systems designed for a single storage layer cannot support all of these demands together. In this talk, I characterize these hardware and software trends and then present Strata, a cross-media file system that leverages the strengths of one storage medium to compensate for weaknesses of another. In doing so, Strata provides performance, capacity, and a simple, synchronous IO model all at once, while having a simpler design than that of file systems constrained by a single storage device. At its heart, Strata uses a log-structured approach with a novel split of responsibilities among user mode, kernel, and storage layers that separates the concerns of scalable, high-performance persistence from storage layer management. On common server workloads, Strata achieves up to 2.6x better IO latency and throughput than the state-of-the-art in low-latency and cross media file systems.
InvasIC Seminar, June 6, 2018 at FAU: Hardware Isolation Framework for Security Mitigation in FPGA-Based Cloud Computing
Prof. Christophe Bobda (University of Arkansas, USA)

The fast integration of FPGA in computing systems (desktop, embedded, cloud and data center) is pushing resources sharing directly in the hardware, away from the operating system. Cloud computing systems is one example where FPGAs are provided as resources that can be share among several tenants. In an infrastructure as a service (IaaS) paradigm, each tenant can access the hardware directly to accelerate some computations as custom circuits in one or more FPGAs. While these systems introduce application programmers to the energy, flexibility, and performance benefits of FPGAs, integrating FPGAs as shared resources into existing clouds pose new security challenges. The sharing of FPGA resources among cloud tenants can lead to scenarios where accelerators are misused as potential covert channels among guests who reside in different security contexts. Among the ten paradigms (Deception, Separation, Diversity, Consistency, Depth, Discretion, Collection, Correlation, Awareness, Response) used to address security vulnerabilities, separation is one of the most effective approach. The Operating systems’ separation kernels have successfully implemented separation at the software level to isolate application-level threads in separate execution domain and contain potential damages caused by malicious components. We hypothesize that computing systems that extend resource sharing to the hardware, such as FPGAs, can be better protected by providing efficient isolation infrastructure that extends system software separation to hardware components. The talk discussed a new security framework that allows controlled sharing and isolated execution of mutually distrusted accelerators in heterogeneous cloud systems. The proposed framework enables the accelerators to transparently inherit software security policies of the virtual machines processes calling them during runtime. This capability allows the system security policies enforcement mechanism to propagate access privilege boundaries expressed at the hypervisor level down to individual hardware accelerators. Furthermore, we present a software/hardware implementation of the proposed security framework that easily and transparently integrates in the hypervisors of today’s cloud systems. Evaluation of security performance and guest VMs execution overhead introduced by the implementation prototype is shows that the proposed framework provides isolated accelerators execution with almost zero execution overhead on guest VMs applications.
InvasIC Seminar, March 26, 2018 at TUM: Opportunities and Challenges of Silicon Photonics for Computing Systems
Prof. Jiang Xu (Hong Kong University of Science and Technology)
Computing systems, from HPC and data center to automobile, aircraft, and cellphone, are integrating growing numbers of processors, accelerators, memories, and peripherals to meet the burgeoning performance requirements of new applications under tight cost, energy, thermal, space, and weight constraints. Recent advances in photonics technologies promise ultra-high bandwidth, low latency, and great energy efficiency to alleviate the inter/intra-rack, inter/intra-board, and inter/intra-chip communication bottlenecks in computing systems. Silicon photonics technologies piggyback onto developed silicon fabrication processes to provide viable and cost-effective solutions. A large number of silicon photonics devices and circuits have been demonstrated in CMOS-compatible fabrication processes. Silicon photonics technologies open up new opportunities for applications, architectures, design techniques, and design automation tools to fully explore new approaches and address the challenges of next-generation computing systems. This talk will present our recent works on holistic comparisons of optical and electrical interconnects, unified optical network-on-chip, memory optical interconnect network, high-radix optical switching fabric for data centers, and etc.
InvasIC Seminar, March 16, 2018 at TUM: Self-Awareness for Heterogeneous MPSoCs: A Case Study using Adaptive, Reflective Middleware
Prof. Nikil Dutt (University of California, Irvine)
Self-awareness has a long history in biology, psychology, medicine, engineering and (more recently) computing. In the past decade this has inspired new self-aware strategies for emerging computing substrates (e.g., complex heterogeneous MPSoCs) that must cope with the (often conflicting) challenges of resiliency, energy, heat, cost, performance, security, etc. in the face of highly dynamic operational behaviors and environmental conditions. Earlier we had championed the concept of CyberPhysical-Systems-on-Chip (CPSoC), a new class of sensor-actuator rich many-core computing platforms that intrinsically couples on-chip and cross-layer sensing and actuation to enable self-awareness. Unlike traditional MPSoCs, CPSoC is distinguished by an intelligent co-design of the control, communication, and computing (C3) system that interacts with the physical environment in real-time in order to modify the system’s behavior so as to adaptively achieve desired objectives and Quality-of-Service (QoS). The CPSoC design paradigm enables self-awareness (i.e., the ability of the system to observe its own internal and external behaviors such that it is capable of making judicious decision) and (opportunistic) adaptation using the concept of cross-layer physical and virtual sensing and actuations applied across different layers of the hardware/software system stack. The closed loop control used for adaptation to dynamic variation -- commonly known as the observe-decide-act (ODA) loop -- is implemented using an adaptive, reflective middleware layer. In this talk I presented a case study of this adaptive, reflective middleware layer using a holistic approach for performing resource allocation decisions and power management by leveraging concepts from reflective software. Reflection enables dynamic adaptation based on both external feedback and introspection (i.e., self-assessment). In our context, this translates into performing resource management actuation considering both sensing information (e.g., readings from performance counters, power sensors, etc.) to assess the current system state, as well as models to predict the behavior of other system components before performing an action. I summarized results leveraging our adaptive-reflective middleware toolchain to i) perform energy-efficient task mapping on heterogeneous architectures, ii) explore the design space of novel HMP architectures, and iii) extend the lifetime of mobile devices.
Events 2017
InvasIC Seminar, October 12, 2017 at TUM: High Performance Computing for Real-Time Applications: A Case Study involving Space-craft Descent on a Planetary Surface
Prof. Amitava Gupta (Jadavpur University, Kolkata, India)
 Space-crafts designed for planetary missions often involve a probe that separates from an orbiter and lands on the planetary surface. Typical
examples of these are the NASA rovers on the Mars and the early lunar missions by the United States and the Soviet Union and in the present
day the attempted descent by the ESA Schiaparelli. Such space-crafts are typically Lander modules which are smaller crafts with limited computing
power and power resources and are endowed with autonomous systems that use imaging to navigate a descent.
Navigation of a lander module starts with an initial hazard map which is a map of the terrain taken from an orbiter hundreds and sometimes
thousands of kilometers above the planetary surface with resolutions as large as several hundred metres. Loading the lander with a more detailed
hazard map poses a constraint in terms of the weight of the imaging equipment and hence the payload to be carried. An alternative approach
is vision guided descent where the onboard imaging equipment associated with the lander progressively refine the terrain image and correct the
lander’s trajectory to identify a suitable landing spot, thus translating the problem to the realm of vision guided control.
Experiments on vision guided landing of toy quadcopters have been successful and is a relatively easier problem as the control algorithm
is not constrained by the limitation that the lander’s displacement can only be towards the planet during descent, unlike a quadcopter, and thus
movements in X-Y direction can be achieved along specific X,Y,Z trajectories depending on the lander’s velocity. This is a tricky job
and requires fast computation with timing and computing power constraints. Thus, this is much different from a quadcopter landing
problem and encompasses several open areas of research like development optimization for processing power and the constraints imposed by the
quantum of change that can be handed by the image processing algorithm on the trajectory control algorithm etc. to name only a few, and thus
links the problem to the realm of High Performance Computing (HPC). Seamless recovery from a processing element failure with migration of
data is another aspect of this problem intimately linked to HPC.
The talk introduced the problem, the motivation of the HPC approach to solve the same and then moved on to identify the processing
elements, connectivity technology and algorithms spanning diverse domains such as image processing, HPC and Embedded Systems and finally
brought out the possibilities of a collaborative research initiative.
Space-crafts designed for planetary missions often involve a probe that separates from an orbiter and lands on the planetary surface. Typical
examples of these are the NASA rovers on the Mars and the early lunar missions by the United States and the Soviet Union and in the present
day the attempted descent by the ESA Schiaparelli. Such space-crafts are typically Lander modules which are smaller crafts with limited computing
power and power resources and are endowed with autonomous systems that use imaging to navigate a descent.
Navigation of a lander module starts with an initial hazard map which is a map of the terrain taken from an orbiter hundreds and sometimes
thousands of kilometers above the planetary surface with resolutions as large as several hundred metres. Loading the lander with a more detailed
hazard map poses a constraint in terms of the weight of the imaging equipment and hence the payload to be carried. An alternative approach
is vision guided descent where the onboard imaging equipment associated with the lander progressively refine the terrain image and correct the
lander’s trajectory to identify a suitable landing spot, thus translating the problem to the realm of vision guided control.
Experiments on vision guided landing of toy quadcopters have been successful and is a relatively easier problem as the control algorithm
is not constrained by the limitation that the lander’s displacement can only be towards the planet during descent, unlike a quadcopter, and thus
movements in X-Y direction can be achieved along specific X,Y,Z trajectories depending on the lander’s velocity. This is a tricky job
and requires fast computation with timing and computing power constraints. Thus, this is much different from a quadcopter landing
problem and encompasses several open areas of research like development optimization for processing power and the constraints imposed by the
quantum of change that can be handed by the image processing algorithm on the trajectory control algorithm etc. to name only a few, and thus
links the problem to the realm of High Performance Computing (HPC). Seamless recovery from a processing element failure with migration of
data is another aspect of this problem intimately linked to HPC.
The talk introduced the problem, the motivation of the HPC approach to solve the same and then moved on to identify the processing
elements, connectivity technology and algorithms spanning diverse domains such as image processing, HPC and Embedded Systems and finally
brought out the possibilities of a collaborative research initiative.
InvasIC Seminar, October 5, 2017 at FAU: Applying Model-Driven Engineering in the co-design of Real-Time Embedded Systems
Prof. Marco Wehrmeister (Federal University of Technology - Parana)
This talk presented methods and techniques applied in the co-design of real-time embedded systems, specifically those that are implemented as a System-on-Chip (SoC) that includes components with reconfigurable logic (FPGA). The target application domain is automation systems. The main objective is to discuss techniques and methods that use high-level abstractions, such as UML/MARTE models and concepts of the Aspect-Oriented Software Development (AOSD), for an integrated co-design addressing both software and hardware design. To this end, introduce model-driven engineering (MDE) techniques were introduced combined with separation of concerns in the handling of functional and non-functional requirements. Automatic transformations between models allow the information specified in different high-level modeling languages to be integrated and shared within the (co-)design of the hardware and software components. To illustrate such transformations, code generation techniques were presented for software components (e.g., java and C / C++) and hardware (VHDL) applied in a case study that represents a real application. Results indicate that the abstraction increase obtained by using MDE and the separation of concerns leads to an improvement in the reuse and adaptation of software components. Thus, by applying these ideas in the design of hardware components in FPGA, one can obtain similar benefits.
click here for the video version with slides
InvasIC Seminar, July 14, 2017, at TUM: Learning-Based Models for Power- and Performance-Aware System Design
Prof. Andreas Gerstlauer (University of Texas at Austin, USA)
Next to performance, power and energy efficiency is a key challenge in computer systems today. Fundamentally, energy efficiency is achieved by reducing computational overhead or effort through specializations or approximations. Both require tight co-design of application-specific architectures. Traditionally, slow simulations or inaccurate analytical methods are used to perform corresponding optimization. In the first part of this talk, I will present our work on fast yet accurate alternatives for early power and performance estimation to support hardware and software design and optimization. In the past, we have pioneered semi-analytical source-level and host-compiled simulation techniques. More recently, we have studied approaches that employ advanced machine learning techniques to synthesize models that can accurately predict power and performance of a target platform purely from characteristics obtained while running an application natively or in a fast functional simulation on a different host. We have developed such learning-based approaches for both hardware accelerators as well as software on CPUs. In the second part of the talk, I will further discuss our work on employing a variety of modeling approaches to design energy-efficient systems through hardware specializations and approximations. We have designed domain-specific accelerators that achieve orders of magnitude improved power/performance efficiencies for dense linear algebra operations, which are at the core of almost all scientific, signal processing and machine learning applications. Furthermore, we have developed systematic and automated methods for design and synthesis of accelerators that employ a range of hardware approximations to support novel types of quality-energy tradeoffs during system exploration.
InvasIC Seminar, July 12, 2017, at TUM: Data-Driven Resiliency Solutions for Integrated Circuits and Systems
Prof. Krishnendu Chakrabarty (Duke University, USA)
Design-time solutions and guard-bands for resilience are no longer sufficient for integrated circuits and electronic systems. This presentation described how data analytics and real-time monitoring can be used to ensure that integrated circuits, boards, and systems operate as intended. The speaker first presented a representative critical path (RCP) selection method based on machine learning and linear algebra that allows us to measure the delay of a small set of paths and infer the delay of a much larger pool of paths. In the second part of the talk, the speaker focused on the resilience problem for boards and systems; we are seeing a significant gap today between working silicon and a working board/system, which is reflected in failures at the board and system level that cannot be duplicated at the component level. The speaker described how machine learning, statistical techniques, and information-theoretic analysis can be used to close the gap between working silicon and a working system. Finally, the presenter described how time-series analysis can be used to detect anomalies in complex core router systems.
InvasIC Seminar, May 5, 2017 at FAU: Designing autonomic heterogeneous computing architectures: a vision
Prof. Donatella Sciuto (Politecnico di Milano)
 The resources available on a chip such as transistors and memory, the level of integration and the speed of components have increased dramatically over the years. Even though the technologies have improved, we continue to apply outdated approaches to our use of these resources. Key computer science abstractions have not changed since the 1960's. Operating systems and languages we use were designed for a different era. Therefore, this is the time to think a new approach for system design and use. The Self-Aware computing research leverages the new balance of resources to improve performance, utilization, reliability and programmability.
The main idea is to combine the massively parallel heterogeneous availability of computational resources to autonomic characteristics to create computing systems capable to configure, heal, optimize, protect themselves and improve interaction without the need for human intervention, exploiting capabilities that allow them to automatically find the best way to accomplish a given goal within the specified resources (power budget and performance).
What we are envisioning is a revolutionary computing system that can observe its own execution and optimize its behavior with respect to the external environment, the user desiderata and the applications demands. Imagine providing users with the possibility to specify their desired goals rather than how to perform a task, along with constraints in terms of energy budget, time, and results accuracy. Imagine, further, a computing chip that performs better, according to a set of goals expressed by the user, the longer it runs an application. Such architecture will allow, for example, a hand-held radio to run cooler the longer the connection time, or a system to perform reliably by tolerating hard and transient failures through self healing. This characteristic will not be provided from the outside as an input to the device, as it happens nowadays in system upgrading, but it would rather be intrinsically embedded in the device, according to the target objective and to the inputs from the external environment. This will make such devices particularly well suited for applications of pervasive computing/control among which, for instance, mobile computing systems, adaptive secure infrastructures. The talk presented how autonomic behavior combined with adaptive hardware technologies will enable the systems to change features of their behavior in a way completely different than nowadays systems upgrading, where the new system behavior is defined by the human design effort. Behavior adaptation will rather be intrinsically embedded in the device, and will be based on the target goals and the inputs coming from the external environment.
The resources available on a chip such as transistors and memory, the level of integration and the speed of components have increased dramatically over the years. Even though the technologies have improved, we continue to apply outdated approaches to our use of these resources. Key computer science abstractions have not changed since the 1960's. Operating systems and languages we use were designed for a different era. Therefore, this is the time to think a new approach for system design and use. The Self-Aware computing research leverages the new balance of resources to improve performance, utilization, reliability and programmability.
The main idea is to combine the massively parallel heterogeneous availability of computational resources to autonomic characteristics to create computing systems capable to configure, heal, optimize, protect themselves and improve interaction without the need for human intervention, exploiting capabilities that allow them to automatically find the best way to accomplish a given goal within the specified resources (power budget and performance).
What we are envisioning is a revolutionary computing system that can observe its own execution and optimize its behavior with respect to the external environment, the user desiderata and the applications demands. Imagine providing users with the possibility to specify their desired goals rather than how to perform a task, along with constraints in terms of energy budget, time, and results accuracy. Imagine, further, a computing chip that performs better, according to a set of goals expressed by the user, the longer it runs an application. Such architecture will allow, for example, a hand-held radio to run cooler the longer the connection time, or a system to perform reliably by tolerating hard and transient failures through self healing. This characteristic will not be provided from the outside as an input to the device, as it happens nowadays in system upgrading, but it would rather be intrinsically embedded in the device, according to the target objective and to the inputs from the external environment. This will make such devices particularly well suited for applications of pervasive computing/control among which, for instance, mobile computing systems, adaptive secure infrastructures. The talk presented how autonomic behavior combined with adaptive hardware technologies will enable the systems to change features of their behavior in a way completely different than nowadays systems upgrading, where the new system behavior is defined by the human design effort. Behavior adaptation will rather be intrinsically embedded in the device, and will be based on the target goals and the inputs coming from the external environment.
click here for the video version with slides
InvasIC Seminar, May 3, 2017, at TUM: Bringing Dynamic Control to Real-time NoCs
Prof. Rolf Ernst (TU Braunschweig)
In many new applications, such as in automatic driving, high performance requirements have reached safety critical real-time systems. Static platform management, as used in current safety critical systems, is no more sufficient to provide the needed level of performance. Dynamic platform management could meet the challenge but usually suffers from a lack of predictability and simplicity needed for certification of safety and real-time properties. This especially holds for the Network-on-Chip (NoC) which is crucial for both performance and predictability. In this talk, we proposed the introduction of a NoC resource management controlling NoC resource allocation and scheduling. Resource management is based on a model of the global system state. We provided a protocol and a real-time analysis providing worst-case guarantees for control, NoC communication, and memory access timing. It supports mixed critical systems with different QoS requirements and traffic classes. The protocol uses key elements of a Software Defined Network (SDN) separating the NoC in a (virtual) control and a data plane thereby simplifying dynamic adaptation and real-time analysis. The approach is not limited to a specific network architecture or topology. Significant improvements compared to static NoC scheduling were demonstrated.
InvasIC Seminar, May 3, 2017, at TUM: Potential Impact of Future Disruptive Technologies on Embedded Multicore Computing
Prof. Theo Ungerer (Universität Augsburg)
There is an ever growing need of current and new applications for increased performance in IoT, embedded computing, but also for mid-level and high-performance computing. Because of the foreseeable end of CMOS scaling, new technologies are under development, as e.g. die stacking and 3D chip technologies, Non-volatile Memory (NVM) technologies, Photonics, Resistive or Memristive Computing, Neuromorphic Computing, Quantum Computing, Nanotubes, Graphene, and Diamond Transistors. Some of these technologies are still very speculative and it is hard to predict which ones will prevail. The technologies will strongly impact the hardware and software of future computing systems, in particular the processor logic itself, the (deeper) memory hierarchy, and new heterogeneous accelerators. As disruptive technologies offer many chances they entail also major changes from applications and software systems through to new hardware architectures. One challenge for the Computer Science community is to develop flexible models for the upcoming disruptive technologies to face the problem that it is currently not clear which of the new technologies will be successful. The talk gave an overview about the on-going roadmapping efforts within the EC CSAs Eurolab-4-HPC. The Eurolab-4-HPC roadmap targets a long-term roadmap (2022-2030) for High-Performance Computing (HPC). Because of the long-term perspective and its speculative nature, the roadmapping effort started with an assessment of future computing technologies that could influence HPC hardware and software. An assessment of the technologies and its potential impact (state of August 2016) was described in the Report on Disruptive Technologies for Years 2020-2030 and the Eurolab-4-HPC preliminary roadmap itself. The talk discussed the potential impact of such Disruptive Technologies on future computer architectures and system structures for embedded and cyber-physical systems, and servers.
InvasIC Seminar, March 17, 2017 at FAU: Game-theoretic Semantics of Synchronous Reactions
Prof. Michael Mendler (University of Bamberg)
 The synchronous model of programming, which emerged in the 1980ies and has led to the development of well-known languages such as Statecharts, Esterel, Signal, Lustre, has made the programming of concurrent systems with deterministic and bounded reaction a routine exercise. However, validity of this model is not for free. It depends on the Synchrony Hypothesis according to which a system is invariably faster than its environment. Yet, this raises a tangled compositionality problem. Since a node is in the environment of the every other node, it follows that each node must be faster than every other and hence faster than itself!
This talk presents a game-theoretic semantics of boolean logic defining the constructive interpretation of step responses for synchronous languages. This provides a coherent semantic framework encompassing both non-deterministic Statecharts (as per Pnueli & Shalev) and deterministic Esterel. The talk sketches a general theory for obtaining different notions of constructive responses in terms of winning conditions for finite and infinite games and their characterisation as maximal post-fixed points of functions in directed complete lattices of intensional truth-values.
The synchronous model of programming, which emerged in the 1980ies and has led to the development of well-known languages such as Statecharts, Esterel, Signal, Lustre, has made the programming of concurrent systems with deterministic and bounded reaction a routine exercise. However, validity of this model is not for free. It depends on the Synchrony Hypothesis according to which a system is invariably faster than its environment. Yet, this raises a tangled compositionality problem. Since a node is in the environment of the every other node, it follows that each node must be faster than every other and hence faster than itself!
This talk presents a game-theoretic semantics of boolean logic defining the constructive interpretation of step responses for synchronous languages. This provides a coherent semantic framework encompassing both non-deterministic Statecharts (as per Pnueli & Shalev) and deterministic Esterel. The talk sketches a general theory for obtaining different notions of constructive responses in terms of winning conditions for finite and infinite games and their characterisation as maximal post-fixed points of functions in directed complete lattices of intensional truth-values.
click here for the video version with slides
Events 2016
InvasIC Seminar, December 13, 2016 at TUM: A Novel Cross-Layer Framework for Early-Stage Power Delivery and Architecture Co-Exploration
Prof. Yiyu Shi (University of Notre Dame)
With the reduced noise margin brought by relentless technology scaling, power integrity assurance has become more challenging than ever. On the other hand, traditional design methodologies typically focus on a single design layer without much cross-layer interaction, potentially introducing unnecessary guard-band and wasting significant design resources. Both issues imperatively call for a cross-layer framework for the co-exploration of power delivery (PD) and system architecture, especially in the early design stage with larger design and optimization freedom. Unfortunately, such a framework does not exist yet in the literature. As a step forward, this talk provides a run-time simulation framework of both PD and architecture and captures their interactions. Enabled by the proposed recursive run-time PD model, it handles an entire SoC PD system on-the-fly simulation with <1% deviation from SPICE. Moreover, with a seamless interaction among architecture, power and PD simulators, it has the capability to simulate benchmarks with millions of cycles within reasonable time. A support vector regression (SVR) model is also employed to further speed up power estimation of functional units to millions cycle/second with good accuracy. The experimental results of running PARSEC suite have illustrated the framework’s capability to explore hardware configurations to discover the co-effect of PD and architecture for early stage design optimization. Moreover, it also illustrates multiple over-pessimism in traditional methodologies. For example, by capturing the closed-loop PD and system interaction, the peak-to-peak noise shows 10% reduction, with potentially 7% power saving.
InvasIC Seminar, November 25, 2016 at FAU: Resource Allocation under Uncertainty -- Online Scheduling with Hard Deadlines
Prof. Dr. Nicole Megow (University of Bremen)

 Uncertainty in the input data is an omnipresent issue when solving real-world optimization problems: jobs may take more or less time than originally estimated, resources may become unavailable, jobs/information arrive late, etc. Uncertain data is often modeled through stochastic parameters or as online information that is incrementally revealed. The task is to design algorithms that "perform well" even under uncertainty. Provable performance guarantee are crucial in many applications, e.g., when operating safety-critical systems.
In this talk, we discuss different types of performance guarantees and focus on worst-case guarantees. The main part is devoted to an online scheduling model in which jobs with hard deadlines arrive online over time. The task ist to find a feasible schedule on a minimum number of machines. We design and analyze online algorithms and we mathematically derive performance guarantees. We also discuss the power of job migration and give somewhat surprising bounds.
Uncertainty in the input data is an omnipresent issue when solving real-world optimization problems: jobs may take more or less time than originally estimated, resources may become unavailable, jobs/information arrive late, etc. Uncertain data is often modeled through stochastic parameters or as online information that is incrementally revealed. The task is to design algorithms that "perform well" even under uncertainty. Provable performance guarantee are crucial in many applications, e.g., when operating safety-critical systems.
In this talk, we discuss different types of performance guarantees and focus on worst-case guarantees. The main part is devoted to an online scheduling model in which jobs with hard deadlines arrive online over time. The task ist to find a feasible schedule on a minimum number of machines. We design and analyze online algorithms and we mathematically derive performance guarantees. We also discuss the power of job migration and give somewhat surprising bounds.
InvasIC Seminar, October 19, 2016 at FAU: Security Enhanced Multi-Processor System Architecture for Mixed-Critical Embedded Applications
Dr. Morteza Biglari-Abhari (University of Auckland)
 Complex mixed-critical embedded applications integrate different functionalities to satisfy the performance requirements and take advantage of the available processing power of multi-core systems. The emerging so-called Internet-of- Things (IoT) requires these systems to be connected through the Internet, which creates new challenges to support not only the energy efficiency, low power consumption and reliability, which have been essential criteria to certify these devices, security has also become the first class design concern.
In this talk, an overview of the potential security issues in multiprocessor systems on chip will be presented. Our system-level security approach, which provides isolation of tasks without the need to trust a central authority at run-time for heterogeneous multiprocessor system will be discussed. This approach allows safe use of shared IP with direct memory access, as well as shared libraries by regulating memory accesses.
Complex mixed-critical embedded applications integrate different functionalities to satisfy the performance requirements and take advantage of the available processing power of multi-core systems. The emerging so-called Internet-of- Things (IoT) requires these systems to be connected through the Internet, which creates new challenges to support not only the energy efficiency, low power consumption and reliability, which have been essential criteria to certify these devices, security has also become the first class design concern.
In this talk, an overview of the potential security issues in multiprocessor systems on chip will be presented. Our system-level security approach, which provides isolation of tasks without the need to trust a central authority at run-time for heterogeneous multiprocessor system will be discussed. This approach allows safe use of shared IP with direct memory access, as well as shared libraries by regulating memory accesses.
InvasIC Seminar, September 30, 2016 at FAU: From tamed heterogeneous cores to system wide intrusion tolerance
Dr. Marcus Völp (University of Luxembourg)
After having seen the transition from increasing processor speeds to increasing system-level parallelism and after realizing that energy, not the transistor budget is the limiting factor, a third trend is on the horizon and also already partially happening in todays CMOS systems, a transition from homogeneous to heterogeneous systems. At the same time we see an increasing use of homogeneous and heterogeous manycore systems on a chip in cyber-physical systems (CPS) and CPS infrastructures, systems which are increasingly exposed to advanced and persistent threats such as faults and attacks, not only by casual hackers, but also by highly skilled and well equipped adversaries. In this talk, I present our work on DTUs and their use in the M3 kernel, a hardware mechanisms to uniformly control and coordinate wildly heterogeneous systems. By wildly heterogeneous we mean heterogeneous systems built with standard doped CMOS technologies that are gradually augmented with circuits and devices built from emerging meterials such as silicon nanowires or carbon nanotubes or that integrate the sensory and interfaces to conncet to novel computing fabrics such as microchemomechanical labs-on-a-chip. In the second part of this talk, I then focus on my current activities in the CritiX group of SNT - University of Luxembourg, sharing our plans and early results for making systems more tolerant to advanced and persistent threats.
click here for the video version with slides
IEEE CEDA Distinguished Lecture at InvasIC Seminar, September 19, 2016 at FAU: High-Level Synthesis and Beyond
Chancellor's Prof. Jason Cong (University of California, Los Angeles)


Ten year ago in SOCC’2006, my group presented xPilot – the high-level synthesis (HLS) tool developed at UCLA for automatic synthesis of behavior-level C/C++ specifications into highly optimized RTL code. In the same year, the startup company AutoESL was formed to commercialize our research on HLS – an effort that many EDA companies tried but failed for over two decades. The AutoESL tool (renamed to Vivado HLS after Xilinx acquisition in 2011) becomes probably the most successful and most widely used HLS tool in the history, now available to tens of thousands of users from companies and universities worldwide. In this talk, I shall first share the lessons that we learned from our HLS project. Then, I shall discuss the exciting opportunity for customized computing in data centers enabled by a robust HLS technology. I shall discuss our recent research on (i) source-code level transformation and optimization for efficient accelerator designs, such as polyhedral-based data reuse optimization and code generation, uniform and non-uniform memory partitioning, and simultaneous computation and communication optimization; and (ii) datacenter-level runtime management for transparent and efficient accelerator utilization. I shall highlight some key progresses in these directions.
InvasIC Seminar, August 8, 2016 at FAU: Adaptive Parallel and Distributed Software Systems
Dr. Pramod Bhatotia (TU Dresden)
Parallel and distributed systems are a pervasive component of the modern computing environment. Today, large-scale data-centers or supercomputing facilities have become ubiquitous, consisting of heterogeneous geo-distributed clusters with 100s of thousands of general-purpose multicores, energy-efficient cores, specialized accelerators such as GPUs, FPGAs, etc. Such computing infrastructure powers not only some of the most popular consumer applications--Internet services such as web search and social networks--but also a growing number of scientific, big data, and enterprise workloads. Due to the growing importance of these diverse applications, my research focuses on building software systems for this new computing infrastructure. In this talk, I present an overview of my research group "Parallel and Distributed Systems" at TU Dresden. The mission of my group is to build adaptive software systems targeting parallel and distributed computing. For adaptiveness, we follow three core design principles: (1) _Resiliency_ against fail-stop and Byzantine faults for ensuring the safety and security of applications; (2) _Efficiency_ of applications by enabling a systematic trade-off between the application performance (latency/throughput) and resources utilization/energy consumption; and (3) _Scalability_ to seamlessly support ever growing application workload with increasing number of cores, and at the same time, embracing the heterogeneity in the underlying computing platform. As I show in my talk, we follow these three design principles at all levels of the software stack covering operating systems, storage/file-systems, parallelizing compilers and run-time libraries, and all the way to building distributed middlewares. Our approach transparently supports existing applications -- we neither require a radical departure from the current models of programming nor complex, error-prone application-specific modifications.
click here for the video version with slides
InvasIC Seminar, August 5, 2016 at FAU: Bridging the gap between embedded systems and automation systems
Prof. Partha S. Roop (University of Auckland)

 Cyber-physical systems use distributed controllers for controlling physical processes. In this talk, we adopt the synchronous approach for the design of CPS and illustrate how the same approach can be leveraged for the design of closed-loop control systems encompassing the plant and the adjoining controller. We adopt the IEC61499 standard and discuss synchronous execution semantics of the standard that enables the design of both the cyber and the physical aspects of the overall system. We also elaborate on the emulation-based validation of controllers using the concept of a plant-on-a-chip (PoC). The proposed approach bridges the gap between two divergent domains, namely embedded systems and automation systems using the developed synchronous semantics.
Cyber-physical systems use distributed controllers for controlling physical processes. In this talk, we adopt the synchronous approach for the design of CPS and illustrate how the same approach can be leveraged for the design of closed-loop control systems encompassing the plant and the adjoining controller. We adopt the IEC61499 standard and discuss synchronous execution semantics of the standard that enables the design of both the cyber and the physical aspects of the overall system. We also elaborate on the emulation-based validation of controllers using the concept of a plant-on-a-chip (PoC). The proposed approach bridges the gap between two divergent domains, namely embedded systems and automation systems using the developed synchronous semantics.
InvasIC Seminar, May 6, 2016 at FAU:Control-theoretic approaches to Energy Minimization under Soft Real-Time Constraints
Prof. Martina Maggio (Lund University)

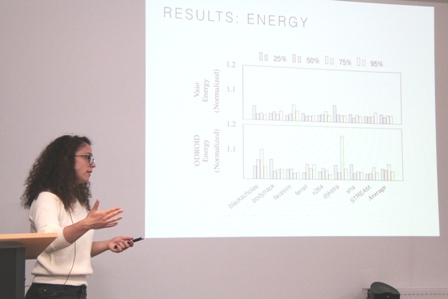 Embedded real-time systems must meet timing constraints while minimizing energy consumption. To this end, many energy optimizations are introduced for specific platforms or specific applications. These solutions are not portable, however, and when the application or the platform change, these solutions must be redesigned. Portable techniques are hard to develop due to the varying tradeoffs experienced with different application/platform configurations. This talk addresses the problem of finding and exploiting general tradeoffs, using control theory and mathematical optimization to achieve energy minimization under soft real-time application constraints. The talk will discuss the general idea behind the use of control theory for optimizing the behavior of computing systems and will delve into details about energy optimization with deadline constraints, presenting results obtained on different architectures - thus considered portable - and with different benchmarks. The use of control theory and system identification enables the exploitation of the mentioned tradeoffs on different architectures.
Embedded real-time systems must meet timing constraints while minimizing energy consumption. To this end, many energy optimizations are introduced for specific platforms or specific applications. These solutions are not portable, however, and when the application or the platform change, these solutions must be redesigned. Portable techniques are hard to develop due to the varying tradeoffs experienced with different application/platform configurations. This talk addresses the problem of finding and exploiting general tradeoffs, using control theory and mathematical optimization to achieve energy minimization under soft real-time application constraints. The talk will discuss the general idea behind the use of control theory for optimizing the behavior of computing systems and will delve into details about energy optimization with deadline constraints, presenting results obtained on different architectures - thus considered portable - and with different benchmarks. The use of control theory and system identification enables the exploitation of the mentioned tradeoffs on different architectures.
click here for the video version with slides
InvasIC Seminar, April 15, 2016 at TUM:Revisiting the Perfect Chip Paradigm: Cross-Layer Approaches to Designing and Monitoring Reliable Systems using Unreliable Components
Prof. Fadi Kurdahi (University of California, USA)
With advanced process nodes the impact of design details on performance increases, making it increasingly expensive --and soon prohibitive-- to guarantee 100% error free chips. The challenge now is how to design reliable systems using circuits that may have faults due to manufacturing process fluctuations, exasperated by environmental factors such as voltage and temperature variations. This talk addresses this notion of error-awareness across multiple abstraction layers – application, architectural platform, and technology – for next generation SoCs. As an example, one may investigate methods to achieve acceptable QoS at different abstraction levels as a result of intentionally allowing errors to occur inside the hardware with the aim of trading that off for lower power, higher performance and/ or lower cost. An ideal context for the convergence of such applications is handheld multimedia communication devices in which a 3G, 4G or similar modem and an H.264 encoder must co-exist, potentially with other applications such as imaging. This cross-layer paradigm requires powerful monitoring infrastructure that is more expressive than today’s capabilities and will be required in the future as SoCs become more complex. We will also discuss the exploitation of such a paradigm in the ecosystems surrounding embedded systems, and show examples of such systems.
InvasIC Seminar, March 4, 2016 at FAU:Bytespresso, toward embedded domain-specific languages for supercomputing
Prof.Shigeru Chiba (University of Tokyo)
As complex hardware architecture is widely adopted in high-performance computing (HPC), average HPC programmers are faced with serious difficulties in programming in a general-purpose language. Thus domain-specific languages (DSLs) are actively studied for HPC as a solution. DSLs are categorised into external DSLs and embedded DSLs. The latter DSLs are easy to develop but its expressiveness and execution performance are drawbacks. This talk present two techniques we are developing. The first one is protean operators, which give DSLs more flexible syntax, and the latter is deep reification, which is a language mechanism for helping DSL developers implement a more efficient DSL. Bytespresso is our prototype system to examine the idea of deep reification in Java. It is a platform of embedded DSLs in which DSL code is offloaded to external hardware for execution after domain-specific translation.
click here for the video version with slides
InvasIC Seminar, Febuary 24, 2016 at TUM:Hyperion
Martin Vorbach (PACT XPP Technologies)
Herr Martin Vorbach, der bereits vor einigen Jahren wesentlich an der Enticklung einer rekonfigurierbaren Prozessorarchitektur (PACT XPP) beteiligt war, stellte Konzepte zu einem neuen Architekturdesign namens Hyperion vor.
InvasIC Seminar, January 29, 2016 at FAU:Elastic Computing - Towards a New Paradigm for Distributed Systems
Prof. Schahram Dustdar (TU Wien)
 In this talk, which is based on our newest findings and experiences from research and industrial projects, I addressed one of the most relevant challenges for a decade to come: How to integrate the Internet of Things with software, people, and processes, considering modern Cloud Computing and Elasticity principles. Elasticity is seen as one of the main characteristics of Cloud Computing today. Is elasticity simply scalability on steroids? This talk addresses the main principles of elasticity, presents a fresh look at this problem, and examines how to integrate people, software services, and things into one composite system, which can be modeled, programmed, and deployed on a large scale in an elastic way. This novel paradigm has major consequences on how we view, build, design, and deploy ultra-large scale distributed systems.
In this talk, which is based on our newest findings and experiences from research and industrial projects, I addressed one of the most relevant challenges for a decade to come: How to integrate the Internet of Things with software, people, and processes, considering modern Cloud Computing and Elasticity principles. Elasticity is seen as one of the main characteristics of Cloud Computing today. Is elasticity simply scalability on steroids? This talk addresses the main principles of elasticity, presents a fresh look at this problem, and examines how to integrate people, software services, and things into one composite system, which can be modeled, programmed, and deployed on a large scale in an elastic way. This novel paradigm has major consequences on how we view, build, design, and deploy ultra-large scale distributed systems.
click here for the video version with slides
Events 2015
InvasIC Seminar, December 21st, 2015 at TUM: Parallelization-in-time for Climate and Weather
Dr. Martin Schreiber (University of Exeter)
Over the last decade, the key component for increasing the compute performance for HPC systems was an increase in data parallelism. However, for simulations with a fixed problem size, this increase in data parallelism clearly leads to circumstances with the communication latency dominating the overall compute time which again results in a stagnation or even decline of scalability. For weather simulations, further requirements on wall clock time restrictions are given and exceeding these restrictions would make these simulation results less beneficial. In this circumstance, time-parallelism is a possible route to explore. In fact, time-parallel techniques have been studied for over 50 years and have been successful when the stiffness of the underlying PDEs is dissipative. Recent advances also address oscillatory stiffness, making time-parallel techniques relevant to weather and climate simulations. This presentation focuses on a new degree of parallelization for the linear operator of the rotational shallow-water equations. Such an approach directly leads to enhanced scalability for moderate problem sizes. Furthermore, an extension of this new degree of parallelization towards dynamic resources is discussed. This new degree in parallelization poses new possibilities for iMPI and contributes to Invasive Computing with a new parallelization pattern.
InvasIC Seminar, December 10, 2015 at TUM: Integrated Circuit Test Structures: Lessons Learned
Dr. Sani Nassif
Integrated circuit manufacturing technology is getting ever more complex, and that makes measuring its behavior difficult. Phenomena such as manufacturing variability, lack of modeling fidelity, non-stationarity, and many others make it hard to “measure” something without that measurement being clouded with noise and inaccuracy. This talk will review a number of principles and techniques which were developed while the author was at IBM to create test structures which are capable of assessing the health of a technology.
InvasIC Seminar, November 30th, 2015 at TUM: Data-driven Online Adaptive Model Reduction For Outer Loop Applications
Dr. Benjamin Peherstor (Massachusetts Institute of Technology)
Model reduction derives low-cost reduced systems of large-scale systems of equations. Traditionally, the computational procedure of model reduction is split into an offline phase, where the reduced system is constructed from solutions of the full-order system, and an online phase, where the reduced system is solved to generate approximations of the full-order solutions for the task at hand. Thus, in this classical offline/online splitting, the reduced system is built once offline with high computational costs and then stays fixed while it is repeatedly solved online; however, in many outer loop applications (e.g., optimization, Bayesian inference, uncertainty quantification) the accuracy and runtime requirements on the reduced system change during the solves in the online phase. We therefore break with the classical and rigid splitting into offline/online phase and adapt the reduced system online. In our approach, when an adaptation is initiated online, the reduced model solves are stopped and a data generation process is started that queries the full-order system. This means that during the online phase, a computationally cheap task (reduced model solve) is occasionally interrupted by an expensive one (data generation), for which sufficient computational resources have to be provided immediately. From the generated data, low-rank updates to the reduced system are derived. We show on examples from uncertainty quantification that our online adaptive approaches often outperform classical model reduction techniques with respect to runtime and accuracy. The examples also demonstrate that through adaptivity, our reduced systems provide valid approximations of the full-order system behaviors that were neglected during the initial building in the offline phase. The computation work flow with alternating cheap task (reduced model solve) and expensive one (data generation) requires change of resources at runtime, if efficiency were to be taken into account. These applications can be well fitted into the invasive HPC paradigm.
InvasIC Seminar, November 27, 2015, 10:00 am at FAU: Energy-Efficient Algorithms
Prof. Dr. Susanne Albers (TU München)
 We study algorithmic techniques for energy savings in computer systems. Research in this area concentrates mostly on two topics. (1) Power-down mechanisms: When a system is idle, it can be transitioned into low power stand-by or sleep states. The goal is to find state transition schedules that minimize the total energy consumption. (2) Dynamic speed scaling: Many modern microprocessors can operate at variable speed. Here the objective is to utilize the full speed/frequency spectrum of a processor so as to optimize the consumed energy and possibly a second QoS measure. This lecture investigates a variety of settings and presents recent research results. The focus is on the design of algorithms that achieve a provably good performance.
We study algorithmic techniques for energy savings in computer systems. Research in this area concentrates mostly on two topics. (1) Power-down mechanisms: When a system is idle, it can be transitioned into low power stand-by or sleep states. The goal is to find state transition schedules that minimize the total energy consumption. (2) Dynamic speed scaling: Many modern microprocessors can operate at variable speed. Here the objective is to utilize the full speed/frequency spectrum of a processor so as to optimize the consumed energy and possibly a second QoS measure. This lecture investigates a variety of settings and presents recent research results. The focus is on the design of algorithms that achieve a provably good performance.
click here for the video version with slides
InvasIC Seminar, November 20, 2015 at FAU: Real-Time Operating Systems for Multicore Platforms: Scheduling, Locking, and Open Problems
Dr. Björn B. Brandenburg (Max Planck Institute for Software Systems)
The rise of multicore processors has necessitated a fundamental rethinking of how predictable real-time operating systems are designed. In particular, as the multicore designs proliferated, it was not all obvious how to "best" schedule the (increasingly many) available cores, or how to enable efficient inter-core synchronization. As a result, the real-time literature has accumulated a bewildering array of potential solutions — including numerous proposals for global, clustered, partitioned, and semi-partitioned scheduling approaches, and various suspension- and spin-based locking protocols, to name just a few categories. However, the right choice in practice is often far from obvious, owing both to the intricate interplay of analytical and engineering concerns in a typical RTOS, and to a not insignificant gap between theory and practice in the real-time literature. Fortunately, research in the past decade has illuminated many of these issues and a clearer picture has emerged. In this talk, based on our experience building LITMUS^RT (http://www.litmus-rt.org), I will first survey and summarize some of the key results and observations in this area, then argue that the multicore scheduling and locking problems are in large parts solved (for practical purposes, in the context of static real-time workloads), and finally highlight avenues for future research by discussing key open problems and shortcomings in current systems.
InvasIC Seminar, October 28, 2015 at FAU: Towards Sentient Chips: Self-Awareness through On-Chip Sensemaking
Chancellor’s Professor Nikil Dutt (University of California, Irvine)

 While the notion of self-awareness has a long history in biology, psychology, medicine, engineering and (more recently) computing, we are seeing the emerging need for self-awareness in the context of complex many-core chips that must address the (often conflicting) challenges of resiliency, energy, heat, cost, performance, security, etc. in the face of highly dynamic operational behaviors and environmental conditions. In this talk I will present the concept of CyberPhysical-Systems-on-Chip (CPSoC), a new class of sensor-actuator rich many-core computing platforms that intrinsically couples on-chip and cross-layer sensing and actuation to enable self-awareness. Unlike traditional MultiProcessor Systems-on-Chip (MPSoCs), CPSoC is distinguished by an intelligent co-design of the control, communication, and computing (C3) system that interacts with the physical environment in real-time in order to modify the system’s behavior so as to adaptively achieve desired objectives and Quality-of-Service (QoS). The CPSoC design paradigm enables self-awareness (i.e., the ability of the system to observe its own internal and external behaviors such that it is capable of making judicious decision) and (opportunistic) adaptation using the concept of cross-layer physical and virtual sensing and actuations applied across different layers of the hardware/software system stack. The closed loop control used for adaptation to dynamic variation -- commonly known as the observe-decide-act (ODA) loop -- is implemented using an adaptive, reflexive middleware layer. The learning abilities of CPSoC provide a unified interface API for sensor and actuator fusion along with the ability to improve autonomy in system management. The CPSoC paradigm is the first step towards a holistic software/hardware effort to make complex chips “sentient”.
While the notion of self-awareness has a long history in biology, psychology, medicine, engineering and (more recently) computing, we are seeing the emerging need for self-awareness in the context of complex many-core chips that must address the (often conflicting) challenges of resiliency, energy, heat, cost, performance, security, etc. in the face of highly dynamic operational behaviors and environmental conditions. In this talk I will present the concept of CyberPhysical-Systems-on-Chip (CPSoC), a new class of sensor-actuator rich many-core computing platforms that intrinsically couples on-chip and cross-layer sensing and actuation to enable self-awareness. Unlike traditional MultiProcessor Systems-on-Chip (MPSoCs), CPSoC is distinguished by an intelligent co-design of the control, communication, and computing (C3) system that interacts with the physical environment in real-time in order to modify the system’s behavior so as to adaptively achieve desired objectives and Quality-of-Service (QoS). The CPSoC design paradigm enables self-awareness (i.e., the ability of the system to observe its own internal and external behaviors such that it is capable of making judicious decision) and (opportunistic) adaptation using the concept of cross-layer physical and virtual sensing and actuations applied across different layers of the hardware/software system stack. The closed loop control used for adaptation to dynamic variation -- commonly known as the observe-decide-act (ODA) loop -- is implemented using an adaptive, reflexive middleware layer. The learning abilities of CPSoC provide a unified interface API for sensor and actuator fusion along with the ability to improve autonomy in system management. The CPSoC paradigm is the first step towards a holistic software/hardware effort to make complex chips “sentient”.
InvasIC Seminar, August 14, 2015 at FAU: Dataflow based Design and Implementation for Multicore Digital Signal Processors
Prof. Dr. Shuvra S. Bhattacharyya (University of Maryland)
 In recent years, we have been seeing increased hardware and software support for dataflow programming incorporated into multicore digital signal processors (MDSPs) and their design environments. Key application areas for such technology include wireless communications, embedded computer vision, and financial signal processing. In this talk, I will discuss challenges in optimized mapping of signal processing dataflow graphs onto state-of-the-art MDSPs, and I will review a number of powerful techniques for dataflow modeling and scheduling that have been developed in recent years to address these challenges. I will conclude with a discussion on emerging trends in the design and implementation of MDSP--based signal processing systems.
In recent years, we have been seeing increased hardware and software support for dataflow programming incorporated into multicore digital signal processors (MDSPs) and their design environments. Key application areas for such technology include wireless communications, embedded computer vision, and financial signal processing. In this talk, I will discuss challenges in optimized mapping of signal processing dataflow graphs onto state-of-the-art MDSPs, and I will review a number of powerful techniques for dataflow modeling and scheduling that have been developed in recent years to address these challenges. I will conclude with a discussion on emerging trends in the design and implementation of MDSP--based signal processing systems.
click here for the video version with slides
InvasIC Seminar, July 24, 2015 at FAU: Proof-Carrying Services
Prof. Dr. Marco Platzner (Universität Paderborn)

 The vision of the Paderborn based cooperative research centre (CRC) 901, On-The-Fly Computing, is the nearly automatic configuration and execution of individualized IT services, which are constructed out of base services traded in world-wide available markets. In this talk, we first briefly overview the goal and the research challenges of the CRC 901 and outline its structure. Then we turn to proof-carrying services, our approach for guaranteeing service properties in the On-The-Fly Computing scenario. The approach builds on the original concept of proof-carrying code, where the producer of a service creates a proof showing that the service adheres to a desired property. The service together with the proof is then delivered to a consumer, that will only execute the service if the proof is both correct and actually about the desired property. On-The-Fly Computing requires us to establish trust in services at runtime and benefits from a main feature of the proof-carrying code concept, which is shifting the burden of creating a proof to the service producer at design time, while at runtime the consumer performs the relatively easy task of checking an existing proof. We extend the concept of proof-carrying code to reconfigurable hardware and show a tool flow to prove functional equivalence of a reconfigurable module with its specification. As a concrete example we detail our work on combined verification of software and hardware for processors with dynamic custom instruction set extensions. We present three variants for combining software and hardware analyses and report on experiments to compare their runtimes.
The vision of the Paderborn based cooperative research centre (CRC) 901, On-The-Fly Computing, is the nearly automatic configuration and execution of individualized IT services, which are constructed out of base services traded in world-wide available markets. In this talk, we first briefly overview the goal and the research challenges of the CRC 901 and outline its structure. Then we turn to proof-carrying services, our approach for guaranteeing service properties in the On-The-Fly Computing scenario. The approach builds on the original concept of proof-carrying code, where the producer of a service creates a proof showing that the service adheres to a desired property. The service together with the proof is then delivered to a consumer, that will only execute the service if the proof is both correct and actually about the desired property. On-The-Fly Computing requires us to establish trust in services at runtime and benefits from a main feature of the proof-carrying code concept, which is shifting the burden of creating a proof to the service producer at design time, while at runtime the consumer performs the relatively easy task of checking an existing proof. We extend the concept of proof-carrying code to reconfigurable hardware and show a tool flow to prove functional equivalence of a reconfigurable module with its specification. As a concrete example we detail our work on combined verification of software and hardware for processors with dynamic custom instruction set extensions. We present three variants for combining software and hardware analyses and report on experiments to compare their runtimes.
click here for the video version with slides
InvasIC Seminar, July 17, 2015 at FAU: Big Data — Small Devices
Prof. Dr. Katharina Morik (TU Dortmund)
 How can we learn from the data of small ubiquitous systems? Do we need to send the data to a server or cloud and do all learning there? Or can we learn on some small devices directly? How complex can learning allowed be in times of big data? What about graphical models? Can they be applied on small devices or even learned on restricted processors?
Big data are produced by various sources. Most often, they are distributedly stored at computing farms or clouds. Analytics on the Hadoop Distributed File System (HDFS) then follows the MapReduce programming model. According to the Lambda architecture of Nathan Marz and James Warren, this is the batch layer. It is complemented by the speed layer, which aggregates and integrates incoming data streams in real time. When considering big data and small devices, obviously, we imagine the small devices being hosts of the speed layer, only. Analytics on the small devices is restricted by memory and computation resources.
The interplay of streaming and batch analytics offers a multitude of configurations. The collaborative research center SFB 876 investigates data analytics for and on small devices regarding runtime, memory and energy consumption. In this talk, we investigate graphical models, which generate the probabilities for connected (sensor) nodes.
• First, we present spatio-temporal random fields that take as input data from small devices, are computed at a server, and send results to –possibly different -- small devices.
• Second, we go even further: the Integer Markov Random Field approximates the likelihood estimates such that it can be computed on small devices.
How can we learn from the data of small ubiquitous systems? Do we need to send the data to a server or cloud and do all learning there? Or can we learn on some small devices directly? How complex can learning allowed be in times of big data? What about graphical models? Can they be applied on small devices or even learned on restricted processors?
Big data are produced by various sources. Most often, they are distributedly stored at computing farms or clouds. Analytics on the Hadoop Distributed File System (HDFS) then follows the MapReduce programming model. According to the Lambda architecture of Nathan Marz and James Warren, this is the batch layer. It is complemented by the speed layer, which aggregates and integrates incoming data streams in real time. When considering big data and small devices, obviously, we imagine the small devices being hosts of the speed layer, only. Analytics on the small devices is restricted by memory and computation resources.
The interplay of streaming and batch analytics offers a multitude of configurations. The collaborative research center SFB 876 investigates data analytics for and on small devices regarding runtime, memory and energy consumption. In this talk, we investigate graphical models, which generate the probabilities for connected (sensor) nodes.
• First, we present spatio-temporal random fields that take as input data from small devices, are computed at a server, and send results to –possibly different -- small devices.
• Second, we go even further: the Integer Markov Random Field approximates the likelihood estimates such that it can be computed on small devices.
InvasIC Seminar, June 12, 2015 at FAU: Constructing Time-Predictable MPSoCs -- Never Give up Control
Prof. Dr. Peter Puschner (TU Wien)
Multi-core processors seem to be the solution to cope with the demand for more computational power that is foreseen for next-generation dependable embedded systems. Multicores promise to both outperform single-core processors and consume less energy than high-speed single cores of equivalent performance. Further, the higher computational power per processor raises the hope that the number of computational nodes and the wiring in distributed embedded computer systems can be reduced, thus increasing their robustness. This talk will show that the above-mentioned promises can only be met if the system design follows some key principles. We will discuss these principles and will illustrate how to apply them when constructing hardware and software architectures for embedded multi-core systems that target safety-critical or mixed-criticality real-time applications.
click here for the video version with slides
InvasIC Seminar, June 5, 2015 at FAU: Fault-Tolerant Task Pools
Prof. Dr. Claudia Fohry (Universität Kassel)
 Since the frequency of failures increases with the size of parallel systems, fault tolerance is of crucial importance for scalable computing. While checkpoint/restart is a well-established technique, application-level approaches may be more efficient. Many modern parallel programming systems (e.g. Cilk, OpenMP, X10) use tasks as their central construct for specifying parallelism, thereby replacing the more traditional concepts of threads and processes. Among other advantages, tasks are not bound to a particular processing resource, and thus can be migrated in case of failures and other changes in resource availability. Tasks are maintained in a task pool, which is also a well-known pattern for load balancing of irregular computations. A task pool comprises some set of workers and a data structure. Workers repeatedly take a task out of the pool, process it, possibly insert new tasks etc., until the pool is empty. The talk describes a fault-tolerant algorithm for a particular type of task pool, called the lifeline scheme. This variant is used for global load balancing by the GLB framework of the programming language X10. We developed our algorithm as an extension of this framework.
Since the frequency of failures increases with the size of parallel systems, fault tolerance is of crucial importance for scalable computing. While checkpoint/restart is a well-established technique, application-level approaches may be more efficient. Many modern parallel programming systems (e.g. Cilk, OpenMP, X10) use tasks as their central construct for specifying parallelism, thereby replacing the more traditional concepts of threads and processes. Among other advantages, tasks are not bound to a particular processing resource, and thus can be migrated in case of failures and other changes in resource availability. Tasks are maintained in a task pool, which is also a well-known pattern for load balancing of irregular computations. A task pool comprises some set of workers and a data structure. Workers repeatedly take a task out of the pool, process it, possibly insert new tasks etc., until the pool is empty. The talk describes a fault-tolerant algorithm for a particular type of task pool, called the lifeline scheme. This variant is used for global load balancing by the GLB framework of the programming language X10. We developed our algorithm as an extension of this framework.
InvasIC Seminar, April 28, 2015 at TUM: Pattern-based Parallelization of Sequential Software
Korbinian Molitorisz (Karlsruhe Institute of Technology)
The free lunch of ever increasing clock frequencies is over. Performance-critical sequential software must be parallelized, and this is tedious, hard, buggy, knowledge-intensive, and time-consuming. In order to assist software engineers appropriately, parallelization tools need to consider detection, transformation, correctness, and performance all together.This talk introduces a pattern-based process model that assists in all four parallelization tasks and hence facilitates transforming legacy software that had not been developed with multicore in mind. Our approach uses optimistic parallelization and generates a semantic model with static and dynamic information. With this information we detect parallelizable regions and runtime-relevant tuning parameters. The regions are then transformed to tunable parallel patterns. Our approach enhances traditional parallelization processes with correctness and performance validations. We conducted two separate evaluations to quantify the parallelization process and its implementation from a software engineer’s perspective. We demonstrate speedup, precision, and recall rates that make our approach attractive for experts and inexperienced software engineers alike.
InvasIC Seminar, April 10, 2015 at FAU: Toward Energy-neutral Computational Sensing - Challenges and Opportunities
Prof. Dr. Luca Benini (ETH Zuerich)
 The "internet of everything" envisions trillions of connected objects loaded with high-bandwidth sensors requiring massive amounts of local signal processing, fusion, pattern extraction and classification, coupled with advanced multi-standard/multi-mode communication capabilities. Higher level intelligence, requiring local storage and complex search and matching algorithms, will come next, ultimately leading to situational awareness and truly "intelligent things" harvesting energy from their environment.
From the computational viewpoint, the challenge is formidable and can be addressed only by pushing computing fabrics toward massive parallelism and brain-like energy efficiency levels. We believe that CMOS technology can still take us a long way toward this vision. Our recent results with the PULP (parallel ultra-low power) open computing platform demonstrate that pj/OP (GOPS/mW) computational efficiency is within reach in today's 28nm CMOS FDSOI technology. In the longer term, looking toward the next 1000x of energy efficiency improvement, we will need to fully exploit the flexibility of heterogeneous 3D integration, stop being religious about analog vs. digital, Von Neumann vs. "new" computing paradigms, and seriously look into relaxing traditional "hardware-software contracts" such as numerical precision and error-free permanent storage.
The "internet of everything" envisions trillions of connected objects loaded with high-bandwidth sensors requiring massive amounts of local signal processing, fusion, pattern extraction and classification, coupled with advanced multi-standard/multi-mode communication capabilities. Higher level intelligence, requiring local storage and complex search and matching algorithms, will come next, ultimately leading to situational awareness and truly "intelligent things" harvesting energy from their environment.
From the computational viewpoint, the challenge is formidable and can be addressed only by pushing computing fabrics toward massive parallelism and brain-like energy efficiency levels. We believe that CMOS technology can still take us a long way toward this vision. Our recent results with the PULP (parallel ultra-low power) open computing platform demonstrate that pj/OP (GOPS/mW) computational efficiency is within reach in today's 28nm CMOS FDSOI technology. In the longer term, looking toward the next 1000x of energy efficiency improvement, we will need to fully exploit the flexibility of heterogeneous 3D integration, stop being religious about analog vs. digital, Von Neumann vs. "new" computing paradigms, and seriously look into relaxing traditional "hardware-software contracts" such as numerical precision and error-free permanent storage.
click here for the video version with slides
InvasIC Seminar, March 27, 2015 at FAU: Multi- and Many-Core Architectures - A Trip over a Bumpy Road
Prof. Dr.-Ing. Jörg Nolte (BTU Cottbus–Senftenberg)
 General purpose CPUs with dozens of computing cores are currently reaching the market. Some researchers even expect chips with thousands of computing cores to be available in the foreseeable future. In this talk we will discuss the architectures of some current multi- and many-core CPUs with an emphasis on understanding the hardware foundation of today's parallel computing systems. In particular we will concentrate on the memory hierarchy of these CPUs and the inherent cost of sharing in cache-coherent multi-core systems. Additionally, we will examine typical problems that system designers and application programmers have to solve when they try to utilize such hardware architectures effectively.
General purpose CPUs with dozens of computing cores are currently reaching the market. Some researchers even expect chips with thousands of computing cores to be available in the foreseeable future. In this talk we will discuss the architectures of some current multi- and many-core CPUs with an emphasis on understanding the hardware foundation of today's parallel computing systems. In particular we will concentrate on the memory hierarchy of these CPUs and the inherent cost of sharing in cache-coherent multi-core systems. Additionally, we will examine typical problems that system designers and application programmers have to solve when they try to utilize such hardware architectures effectively.
click here for the video version with slides
InvasIC Seminar, March 27, 2015 at FAU: Building, Programming, and Validating Low-power Heterogeneous Multi-core Image Processors
Dr. Menno Lindwer (Intel Corporation, Eindhoven, The Netherlands)
 Imaging is the criterion of choice for mobile application processors (but also in automotive, print/imaging, digital cameras, and in-home security). Market data shows that buying decisions are driven by many factors which application processor vendors do not control, such as OEM branding, screen size and memory size. Next to those factors, buying decisions are primarily driven by image quality, and other imaging features, such as capture speed, video recording, face recognition, panorama modes, etc. This is the reason that the image signal processor solutions within mobile devices are currently among the largest silicon components. Despite the seemingly homogeneous requirements of pixel processing -- after all, pixels are just parallel color channels -- the actual processing requirements are not only extremely high, but also very diverse. Pixel processing algorithms are being developed at a very high pace. Sensor innovations cause decreases in pixel size, pixel rastering, and increase in noise levels. Many pixel processing algorithms require large 2D kernel fields, moving search spaces, and dynamic programming. All of these domain developments actually result in image processing solutions being highly heterogeneous, and with programmable operation throughputs at Tera-op level.
Yet, these solutions need to fit the power budget of mobile phones. This means that that programming solutions need to perform two tasks which are typically conflicting: increase utilization level of silicon compute resources to above 80%, while at the same time increasing the number of imaging functions that can be brought to the market. The solutions to these conflicting challenges are found in a combination of highly heterogeneous and application-specific processor resources, fully compiler-driven hardware, static schedules, very aggressive compiler optimizations, automatic construction of optimized middleware layers, and rigorous testing at command interface level, rather than at register level.
Imaging is the criterion of choice for mobile application processors (but also in automotive, print/imaging, digital cameras, and in-home security). Market data shows that buying decisions are driven by many factors which application processor vendors do not control, such as OEM branding, screen size and memory size. Next to those factors, buying decisions are primarily driven by image quality, and other imaging features, such as capture speed, video recording, face recognition, panorama modes, etc. This is the reason that the image signal processor solutions within mobile devices are currently among the largest silicon components. Despite the seemingly homogeneous requirements of pixel processing -- after all, pixels are just parallel color channels -- the actual processing requirements are not only extremely high, but also very diverse. Pixel processing algorithms are being developed at a very high pace. Sensor innovations cause decreases in pixel size, pixel rastering, and increase in noise levels. Many pixel processing algorithms require large 2D kernel fields, moving search spaces, and dynamic programming. All of these domain developments actually result in image processing solutions being highly heterogeneous, and with programmable operation throughputs at Tera-op level.
Yet, these solutions need to fit the power budget of mobile phones. This means that that programming solutions need to perform two tasks which are typically conflicting: increase utilization level of silicon compute resources to above 80%, while at the same time increasing the number of imaging functions that can be brought to the market. The solutions to these conflicting challenges are found in a combination of highly heterogeneous and application-specific processor resources, fully compiler-driven hardware, static schedules, very aggressive compiler optimizations, automatic construction of optimized middleware layers, and rigorous testing at command interface level, rather than at register level.
click here for the video version with slides
InvasIC Seminar, March 26, 2015 at FAU: Predictability for Uni- and Multi-Core Real-Time/Cyber-Physical Systems
Prof. Frank Mueller (North Carolina State University)
This talk highlights challenges and contributions in worst-case execution time analysis for real-time system considering architectural changes over time and discusses future trends and open research problems.
click here for the video version with slides
InvasIC Seminar, February 27, 2015 at FAU: Accelerating Data Processing Using FPGAs
Prof. Dr. Jens Teubner (TU Dortmund)
 Field-programmable gate arrays (FPGAs) have reached a complexity (in terms of available logic and memory resources) that makes them attractive to complement or even replace traditional processors. But it remains unclear, how the flexibility of programmable hardware can best be utilized to accelerate typical data processing tasks. The chip's configuration could be re-loaded for every application, every workload, every task, etc. But the high costs of reconfiguration demand a trade-off between flexibility/expressiveness, reconfiguration cost, and runtime performance.
In the talk I will give an answer to the trade-off question for two realistic scenarios from the database domain. First, I will demonstrate how our “skeleton automata” design technique results in a high expressiveness for an XML processing workload—without any concessions on reconfiguration or runtime speed. In my second part, I will give an overview of “Ibex”, which is an FPGA-based storage back-end for the MySQL database. With “Ibex,” a meaningful set of query (sub-)tasks can be pushed down to the system's storage layer, resulting in significant performance and energy advantages.
Parts of this work have been done in collaboration with Louis Woods from ETH Zurich (now with Oracle Labs).
Field-programmable gate arrays (FPGAs) have reached a complexity (in terms of available logic and memory resources) that makes them attractive to complement or even replace traditional processors. But it remains unclear, how the flexibility of programmable hardware can best be utilized to accelerate typical data processing tasks. The chip's configuration could be re-loaded for every application, every workload, every task, etc. But the high costs of reconfiguration demand a trade-off between flexibility/expressiveness, reconfiguration cost, and runtime performance.
In the talk I will give an answer to the trade-off question for two realistic scenarios from the database domain. First, I will demonstrate how our “skeleton automata” design technique results in a high expressiveness for an XML processing workload—without any concessions on reconfiguration or runtime speed. In my second part, I will give an overview of “Ibex”, which is an FPGA-based storage back-end for the MySQL database. With “Ibex,” a meaningful set of query (sub-)tasks can be pushed down to the system's storage layer, resulting in significant performance and energy advantages.
Parts of this work have been done in collaboration with Louis Woods from ETH Zurich (now with Oracle Labs).
click here for the video version with slides
InvasIC Seminar, January 30, 2015 at FAU: Reliable Real-Time Communication in Cyber-Physical Systems: Towards Cooperative Vehicular Networks
Prof. Falko Dressler (University of Paderborn)
Adaptive computing capabilities enable a wide range of new applications in cyber-physical systems. This is often based on smart communication techniques. In this talk, we focus on novel approaches in the context of smart cities using vehicular networking technology as a basis for cooperative maneuvers on the road. Computing capabilities as investigated in the scope of the InvasIC project help establishing such capabilities but have to rely on the capability of the underlying wireless communication network to provide reliable real-time communication. With the standardization of the DSRC/WAVE protocol stack, the vehicular networking community converged to a common understanding of data dissemination schemes that already have high potentials for many applications. Yet, vehicular networks are way more dynamic than originally considered. Radio signal fading and shadowing effects need to be considered in the entire design process as well as the strong need for low-latency communication, fairness, and robustness. In the main part of the talk, examples or basic building blocks for such new IVC protocol will be presented. Putting two application examples into the focus of the discussion, namely intersection warning systems and platooning, we will see that careful congestion control might be counterproductive for safety applications relying on hard real-time capabilities. The optimization goal is to make full use of the wireless channel but prevent overload situations, i.e., collisions, reducing the performance of the transmissions.
Events 2014
InvasIC Seminar, December 17, 2014 at TUM: Quality-Energy Aware Design of Approximate Computing Systems
Prof. Andreas Gerstlauer (The University of Texas at Austin )
Approximate computing is an aggressive design technique aimed at achieving significant energy savings by trading off computational precision and accuracy in inherently error-tolerant applications. This introduces a new notion of quality as a fundamental design parameter. While ad-hoc solutions have been explored at various levels, systematic approaches that span across the compute stack are lacking. In this talk, we present recent work on investigating quality-energy aware system design all the way from basic hardware components to application-level specifications. We first present design strategies for approximate arithmetic units, such as adders and multipliers. A key observation is that there exists a large design space of Pareto-optimal solutions formed by novel methods for approximate Boolean logic synthesis. Such functional units then form the building blocks for approximate hardware and software processors. We further discuss approaches for approximating compilation and synthesis of high-level application models into quality-configurable software or hardware. There, accuracy levels are assigned to individual operations such that energy is minimized while meeting a generic output quality constraint. A key concern is a fast and accurate analytical estimation of arbitrary, application-specific quality metrics under general hardware approximations. The long-term goal is to integrate such optimizations into existing compiler and high-level synthesis frameworks. This in turn will provide the basis for developing novel approaches for combined mapping, scheduling and quality-energy-performance configuration of application tasks running on approximate system platforms. When applying such techniques to the design and optimization of signal processing systems, results at varying levels show that energy savings of 40% are possible while maintaining overall output quality.
InvasIC Seminar, November 21, 2014 at FAU: Making data flow, dynamically
Prof. Twan Basten (Eindhoven University of Technology)
 Many of today's embedded systems are data-intensive. They are moreover more and more often operating in an open, dynamic environment with varying processing workloads and changing resource availability. Dataflow models of computation are well-suited for the model-driven design of data-intensive embedded systems. Traditional dataflow models like synchronous dataflow cannot efficiently cope with the dynamics of modern systems. Novel computational models such as scenario-aware dataflow have been developed to address this challenge. In this presentation, I will present an overview of model-driven embedded-system design using dataflow models, surveying the state of the art in system synthesis and highlighting some remaining challenges.
Many of today's embedded systems are data-intensive. They are moreover more and more often operating in an open, dynamic environment with varying processing workloads and changing resource availability. Dataflow models of computation are well-suited for the model-driven design of data-intensive embedded systems. Traditional dataflow models like synchronous dataflow cannot efficiently cope with the dynamics of modern systems. Novel computational models such as scenario-aware dataflow have been developed to address this challenge. In this presentation, I will present an overview of model-driven embedded-system design using dataflow models, surveying the state of the art in system synthesis and highlighting some remaining challenges.
click here for the video version with slides
InvasIC Seminar, July 17, 2014 at FAU: Power Contracts und eine Einleitung in den kontraktbasierten Entwurf
Gregor Nitsche (Offis - Institut für Informatik, Oldenburg)
Die zunehmende Anzahl komplexer werdender eingebetteter elektronischer Systeme und Mikrochips ist gleichzeitig verbunden mit einer zunehmenden Bedeutung ihrer Energieeffizienz und stellt ihren Entwurfsprozess vor die Herausforderung einer ausreichend verlässlichen Modellierung, Optimierung und Validierung ihrer Leistungsaufnahme während der frühen Phasen des Systementwurfs. Da Präzision und Zuverlässigkeit der Leistungsabschätzung jedoch erst mit dem fortschreitenden Entwurfsprozess zunehmen, basieren geeignete Leistungsmodelle häufig auf bottom-up Charakterisierungs- und Abstraktionsprozessen, deren Gültigkeitsgrenzen oft nur in Form schriftlicher Dokumentationen vorliegen. Um die korrekte Wiederverwendung dieser Leistungsmodelle jedoch auch formal sicherzustellen, verbinden und formalisieren 'Power Contacts' deren Gültigkeitsbeschränkungen in Form formaler Annahmen über die Eingaben des Modells mit formalen Garantien hinsichtlich des Leistungsverhaltens des Systems. Auf Grundlage der kontraktbasierten Methoden zur virtuellen Integration, Kompatibilitätsprüfung und zur Verfeinerung von Komponenten erlauben Power Contracts damit eine verlässlich korrekte bottom-up Wiederverwendung der Leistungsmodelle und ermöglichen so eine frühzeitige Leistungsabschätzung komplex zusammengesetzter Gesamtsysteme.
InvasIC Seminar, July 4, 2014 at FAU: Semantics and Concurrent Data Structures for Dynamic Streaming Languages
Prof. Albert Cohen (École polytechnique, Paris)

 Stream computing is often associated with regular, data-intensive applications, and more specifically with the family of cyclo-static data-flow models. The term also refers to bulk-synchronous data parallelism overlapping computations and communications. Both interpretations are valid but incomplete: streams underline the formal definition of Kahn process networks for 4 decades, a foundation for a more general class of deterministic concurrent languages and systems with a solid heritage. Stream computing is a semantical framework for parallel languages and as a model for pipelined, task-parallel execution. Supporting research on parallel languages with dynamic, nested task creation and first-class streams, we are developing a generic stream-computing execution environment combining expressiveness, efficiency and strong correctness guarantees. In particular, we propose a new lock-free algorithm for stalling and waking-up tasks in a user-space scheduler according to changes in the state of the corresponding queues. The algorithm is portable and proven correct against the C11 weak memory model.
Stream computing is often associated with regular, data-intensive applications, and more specifically with the family of cyclo-static data-flow models. The term also refers to bulk-synchronous data parallelism overlapping computations and communications. Both interpretations are valid but incomplete: streams underline the formal definition of Kahn process networks for 4 decades, a foundation for a more general class of deterministic concurrent languages and systems with a solid heritage. Stream computing is a semantical framework for parallel languages and as a model for pipelined, task-parallel execution. Supporting research on parallel languages with dynamic, nested task creation and first-class streams, we are developing a generic stream-computing execution environment combining expressiveness, efficiency and strong correctness guarantees. In particular, we propose a new lock-free algorithm for stalling and waking-up tasks in a user-space scheduler according to changes in the state of the corresponding queues. The algorithm is portable and proven correct against the C11 weak memory model.
click here for the video version with slides
InvasIC Seminar, June 27, 2014 at FAU: Efficient Computing in Cyber-Physical Systems
Prof. Peter Marwedel (TU Dortmund, Germany)
 Computing in cyber-physical systems (CPS) has to reflect the context of the computations and, hence, has to be efficient in terms of a number of objectives. In particular, computing has to be (worst and average case) execution-time and energy efficient, while also being reliable. In this talk, we will consider optimization techniques targeting energy efficiency and worst-case execution time (WCET) minimization.
In the first part, we will explain how the energy consumption of computing in CPS can be reduced with scratch pad memories (SPMs) and with graphic processing units (GPUs). SPMs and GPUs also help us to meet real-time constraints. We will then look at real-time constraints more closely and consider WCETs minimization. We do this by integrating compilers and WCET estimation. We will demonstrate how such an integration opens the door to WCET-reduction algorithms. For example, an algorithm for mapping frequently accessed memory objects to SPMs is able to reduce the WCET for an automotive application by about 50%. The need to seriously consider WCETs and time constraints also has an impact on applicable error correction techniques in cyber-physical systems. We will demonstrate our approach for a flexible error handling in the presence of real-time constraints which are possibly prohibiting time consuming error corrections.
Computing in cyber-physical systems (CPS) has to reflect the context of the computations and, hence, has to be efficient in terms of a number of objectives. In particular, computing has to be (worst and average case) execution-time and energy efficient, while also being reliable. In this talk, we will consider optimization techniques targeting energy efficiency and worst-case execution time (WCET) minimization.
In the first part, we will explain how the energy consumption of computing in CPS can be reduced with scratch pad memories (SPMs) and with graphic processing units (GPUs). SPMs and GPUs also help us to meet real-time constraints. We will then look at real-time constraints more closely and consider WCETs minimization. We do this by integrating compilers and WCET estimation. We will demonstrate how such an integration opens the door to WCET-reduction algorithms. For example, an algorithm for mapping frequently accessed memory objects to SPMs is able to reduce the WCET for an automotive application by about 50%. The need to seriously consider WCETs and time constraints also has an impact on applicable error correction techniques in cyber-physical systems. We will demonstrate our approach for a flexible error handling in the presence of real-time constraints which are possibly prohibiting time consuming error corrections.
click here for the video version with slides
InvasIC Seminar, June 13, 2014 at FAU: Crown Scheduling: Energy-Efficient On-Chip Pipelining for Moldable Parallel Streaming Tasks
Prof. Christoph Kessler (Linköping University, Sweden)

 We investigate the problem of generating energy-optimal code for the steady state of a pipelined task graph of streaming tasks that include moldable parallel tasks, for execution on a generic manycore processor with dynamic discrete frequency scaling. Pipelined streaming task graphs, which can model data-intensive
computations such as video coding/decoding, signal processing etc., differ from classical task graphs in that, in the steady state of the pipeline, all its tasks are running concurrently, so that cores typically run several tasks that are scheduled round-robin at user level in a data driven way. A stream of data flows through the tasks and intermediate results are forwarded on-chip from producer to consumer tasks. Moldable parallel tasks use internally a parallel algorithm running on any (integer) number of cores simultaneously, and we make no restrictions about the tasks' speedup functions. In this presentation we introduce Crown Scheduling, a novel technique for the co-optimization of resource allocation, mapping and discrete voltage/frequency scaling for moldable streaming tasks in order to achieve optimal energy efficiency subject to a given throughput constraint. We present optimal off-line algorithms for phase-separated and integrated crown scheduling based on integer linear programming (ILP), for any given core energy model. Our experimental evaluation of the ILP models for a generic manycore architecture shows that for small and medium sized task sets even the integrated variant of Crown Scheduling can be solved to optimality by a state-of-the-art ILP solver within a few seconds. For the case of large problem instances we have developed fast Crown Scheduling heuristics.
We investigate the problem of generating energy-optimal code for the steady state of a pipelined task graph of streaming tasks that include moldable parallel tasks, for execution on a generic manycore processor with dynamic discrete frequency scaling. Pipelined streaming task graphs, which can model data-intensive
computations such as video coding/decoding, signal processing etc., differ from classical task graphs in that, in the steady state of the pipeline, all its tasks are running concurrently, so that cores typically run several tasks that are scheduled round-robin at user level in a data driven way. A stream of data flows through the tasks and intermediate results are forwarded on-chip from producer to consumer tasks. Moldable parallel tasks use internally a parallel algorithm running on any (integer) number of cores simultaneously, and we make no restrictions about the tasks' speedup functions. In this presentation we introduce Crown Scheduling, a novel technique for the co-optimization of resource allocation, mapping and discrete voltage/frequency scaling for moldable streaming tasks in order to achieve optimal energy efficiency subject to a given throughput constraint. We present optimal off-line algorithms for phase-separated and integrated crown scheduling based on integer linear programming (ILP), for any given core energy model. Our experimental evaluation of the ILP models for a generic manycore architecture shows that for small and medium sized task sets even the integrated variant of Crown Scheduling can be solved to optimality by a state-of-the-art ILP solver within a few seconds. For the case of large problem instances we have developed fast Crown Scheduling heuristics.
InvasIC Seminar, May 8, 2014 at TUM: An Asymptotic Parallel-in-Time Method for Highly Oscillatory PDEs
Prof. Beth Wingate (University of Exeter, England)
In this talk I will present a new algorithm for achieving parallel-in-time performance for highly oscillatory PDEs and show results with the shallow water equations. I will show that the parallel speed-up increases as the time scale separation increases which results in an arbitrarily greater efficiency gain relative to standard numerical integrators. I also present numerical experiments for the doubly periodic shallow water equations that demonstrate the parallel speed up is more than 100 relative to exponential integrators such as ETDRK4 and more than 10 relative to the standard parareal method with a linearly exact coarse solver. Finally I will show that the method also works in the absence of time scale separation, allowing for the method to work in different model regimes. In order to begin a discussion about how this method will work on parallel machines I will introduce a new method for computing linear propagators in a very parallel-way and will present some questions about the type of parallelism an algorithm like this could have for heterogeneous computing architectures.
InvasIC Seminar, March 21, 2014 at FAU:

Prof. Tulika Mitra (National University of Singapore) Heterogeneous Multi-cores in the Dark Silicon Era
Moore's Law enables continued increase in the number of cores on chip; but power and thermal limits imply that a significant fraction of these cores have to be left switched off --- or dark --- at any point in time. This phenomenon, known as dark silicon, is driving the emergence of heterogeneous/asymmetric computing platforms consisting of cores with diverse power-performance characteristics enabling better match between the application requirements and the compute engine leading to substantially improved energy-efficiency. In this talk, we present the challenges and opportunities offered by static and adaptive heterogeneous multi-cores towards low-power, high-performance mobile computing. For static asymmetric multi-cores, we present a comprehensive power management framework that can provide high performance while minimizing energy consumption within the thermal design power budget. We then describe an adaptive heterogeneous multi-core architecture, called Bahurupi, that can be tailored according to the application by software. Bahurupi is designed and fabricated as a homogeneous multi-core system containing identical simple cores. Post-fabrication, software can configure or compose together the primitive cores to create a heterogeneous multi-core that best matches the needs of the currently executing application.
click here for the video version with slides
InvasIC Seminar, March 21, 2014 at FAU:
Prof. Brett Meyer (McGill University, Canada) Execution Stream Fingerprinting for Low-cost Safety-critical System Design
Recently, the combination of semiconductor manufacturing technology scaling and pressure to reduce semiconductor system costs and power consumption has resulted in the development of computer systems responsible for executing a mix of safety-critical and non-critical tasks. However, such systems are poorly utilized if lockstep execution forces all processor cores to execute the same task even when not executing safety-critical tasks. Execution fingerprinting has emerged as an alternative to n-modular redundancy for verifying redundant execution without requiring that all cores execute the same task or even execute redundant tasks concurrently. Fingerprinting takes a bit stream characterizing the execution of a task and compresses it into a single, fixed-width word or fingerprint. Fingerprinting has several key advantages. First, it reduces redundancy-checking bandwidth by compressing changes to external state into a single, fixed-width word. Second, it reduces error detection latency by capturing and exposing intermediate operations on faulty data. Third, it naturally supports the design of mixed criticality systems by making dual-, triple-, and n-modular redundancy available without requiring significant architectural changes. Fourth, while it can’t guarantee perfect error detection, error detection probabilities and latencies can be tuned to a particular application. Together, these advantages translate to improved performance for mixed-criticality systems. In this talk, I will describe fingerprinting in safety-critical systems and explore the various trade-offs inherent in its application at the architectural level and choices related to fingerprinting subsystem design, including: (a) determining what application data to compress, as a function of error detection probability and latency, and (b) identifying a corresponding fingerprinting circuit implementation.
click here for the video version with slides
InvasIC Seminar, March 21, 2014 at FAU:
Prof. Philip Brisk (University of California, Riverside) An Application-Specific Processor for Real-Time Medical Monitoring
The last decade has seen significant advances in creating bedside monitoring algorithms for a host of medical conditions; however surprisingly few of these algorithms have seen deployment in wearable devices. The obvious difficulty is the availability of computational resources on a device that is small enough to be convenient and unobtrusive. The computational resource gap between conventional systems and wearable devices can be partly bridged by optimizing the algorithms (admissible pruning, early abandoning, indexing, etc.), but increasingly sophisticated monitoring algorithms have produced an arms race that is outpacing the performance and energy capabilities of the hardware community. Within this context, application- and domain-specialization are ultimately necessary in order to achieve the highest possible efficiency for wearable computing platforms. Medical monitoring is a specialized form of time series data mining. Most time series data mining algorithms require similarity comparisons as a subroutine, and there is increasing evidence that the Dynamic Time Warping (DTW) measure outperforms the competition in most domains, including medical monitoring. In addition to medical monitoring, DTW has been used in diverse domains such as robotics, medicine, biometrics, music/speech processing, climatology, aviation, gesture recognition, user interfaces, industrial processing, cryptanalysis, mining of historical manuscripts, geology, astronomy, space exploration, wildlife monitoring, and many others. Despite its ubiquity, DTW remains too computationally intensive for use in real-time applications because its core is a dynamic programming algorithm that has a quadratic time complexity; however, recent algorithmic optimizations have enabled DTW to achieve near-constant amortized time when processing time series databases containing trillions of elements. As further software optimization appears unlikely to yield any further improvements, attention must be turned to hardware specialization. This talk will present the design, implementation, and evaluation of an application-specific processor whose instruction set has been customized to accelerate a software-optimized implementation of DTW. Compared to a 32-bit embedded processor, our design yields a 4.87x improvement in performance and a 78% reduction in energy consumption when prototyped on a Xilinx EK-V6-ML605-G Virtex 6 FPGA.
click here for the video version with slides
InvasIC Seminar, February 18, 2014, 3p.m. at TUM: GungHo!ing Weather and Climate
Dr. Iva Kavčič (University of Exeter, UK)
Gung Ho (Globally Uniform Next Generation Highly Optimized) is a 5 year project with the aim to research, design and develop a new dynamical core suitable for operational, global and regional, weather and climate simulation on massively parallel computers of the size envisaged over the coming 20 years. A dynamical core of any numerical weather prediction (NWP) and climate model is the discretization of governing equations representing atmospheric motions that can be resolved on the model grid. The project is a UK based collaboration of GFD, numerical and computational scientists from various universities, led by the Met Office and supported by the Science and Technology Facilities Council (STFC). First I will give a general overview on how weather and climate models are made, with an example of the Met Office’s Unified Model (UM). Then I will talk about different aspects and challenges in constructing a new dynamical core in the GungHo project. Some of the questions are: What should replace the lat-lon grid and how to transport material on that grid; Viability of explicit vs. implicit time schemes; Code design and computational science aspects.
Events 2013
InvasIC Seminar, December 5, 2013 at TUM: Computational and Numerical Challenges in Weather Prediction
Andreas Mueller (NPS, Monterey)
Significant progress in numerous areas of scientific computing comes from the steadily increasing capacity of computers and the advances in numerical methods. An example is the simulation of the Earth’s atmosphere, which has proven to be extremely challenging owing to its multiscale and multi-process nature. Even with today’s computers it is impossible to explicitly represent all scales and all processes involved. This talk aims at presenting an overview of computational and numerical challenges in weather prediction. After giving a basic introduction into numerical weather prediction the following open questions will be discussed: 1. How can we approximate non-resolved scales (by using so called parameterizations) in a way that is resolution-aware and preserves the order of accuracy of the numerical method? 2. How can we estimate the error without having convergence? 3. Which numerical methods should we use? 4. How can we optimize our code without sacrificing readability? 5. How can we reduce communication between the computing nodes? 6. How can we develop refinement criteria for using adaptive mesh refinement in global weather simulations? and 7. How can we adapt the computational resources to occurring extreme weather events? » more information.
InvasIC Seminar, November 22, 2013, at FAU: Dynamisches Task-Scheduling in heterogenen Mehrprozessorsystemen
Oliver Arnold (TU Dresden)
Simultaneously improving both, computational power and energy efficiency, represents one of the major challenges in the development of future hardware systems. In this regard, the systems' manufacturing process as well as the hardware architecture must be examined. Concerning architecture design, the combination of different types of processing elements (PEs) in a single chip, is a recent trend. A smart management of these PEs allows an increase in computational power as well as energy efficiency. In this work a dedicated scheduling unit called CoreManager is proposed to control heterogeneous Multiprocessor Systems-on-Chips (MPSoCs). This unit is responsible for dynamically distributing atomic tasks on different PEs as well as managing the inherent data transfers. For this purpose, a runtime analysis of the data dependencies is firstly performed. Based on this analysis, a schedule is created to allocate the PEs and explicitly reserve and administrate the local memories. The results of the dynamic data dependency analysis are additionally reused in order to increase data locality. In particular, required data are kept in the local memories, thus reducing the number of transfers from the global memories. The CoreManager has been profiled in order to expose the most time consuming components. Dynamic data dependency check was found to be the limiting factor regarding system scalability. An extension of the instruction set architecture of the CoreManager has been developed and integrated to solve this issue. This extension allows speeding-up the data dependency check process and other CoreMangager components, thus increasing performance while reducing energy consumption. A battery-aware mode of operation of the CoreManager is introduced, which allows extending the lifetime of the system. Furthermore, a failure-aware dynamic task scheduling approach for unreliable heterogeneous MPSoCs was integrated in the CoreManager. It enables a detection and isolation of erroneous PEs, connections and memories. By applying these approaches the efficient management of heterogeneous MPSoCs is enabled.
InvasIC Seminar, November 14, 2013 at TUM: Lyapunov Exponents & the Stability of Structures Under Random Perturbations
Prof. Dr. Florian Rupp (Department of Mathematics and Analytica Mechanics, TUM)
Our guest researcher Florian Rupp gave a talk on modeling and simulation of randomly perturbed structures using stochastic processes and Lyapunov exponent. This represents an algorithmic class so far not considered for Invasive Computing. He presented the Wolf algorithm with a random number generator used for input values. Simulations of such models require up to 200k time steps with many simulation instances being executed in parallel. Hence, it is possible to execute each simulation instance independent of others, thus yielding an embarrassingly parallel execution and therefore new challenges and perspectives for Invasive Computing.
InvasIC Seminar, November 13, 2013 at TUM: Network-on-Chip Cross-Layer Design and Optimization to Enable Flexible Space and Time Partitioning in Many-Core Systems
Davide Bertozzi (University of Ferrara)
Many-core architectures represent today the reference design paradigm for high-end systems-on-chip, and for embedded GPUs in medium-to-high-end SoCs. It is highly unlikely that single applications can monolithically exploit the unprecedented level of hardware parallelism that these platforms are able to expose. As a consequence, the most likely paradigm for the successful exploitation of many-core architectures consists of space and time partitioning, combined with the custom adaptation of partition settings to the workload at hand. In this context, the on-chip interconnection network cannot be viewed as a simple communication fabric, but it takes on the role of system integration and control framework. This presentation addresses both the integration and the runtime configuration challenge for networks-on-chip in the many-core era, by proposing ad-hoc design techniques at the most suitable abstraction layers. At the architectural level, industry-relevant asynchronous interconnect technology will be demonstrated to absorb system heterogeneity stemming from different operating voltages and speed. At the system level, overlapped static reconfiguration techniques will be presented, capable of achieving the runtime reconfiguration of the NoC routing function without draining the network from ongoing traffic. Last but not least, the programming model implications will be derived for general-purpose programmable accelerators to program and master such a highly dynamic environment. The presentation will finally sketch the role that the emerging optical interconnect technology might play in this context, and its status with respect to the use of an aggressive electrical baseline. more information
InvasIC Seminar, July 17, 2013 at FAU: Intelligente Straßenverkehrssteuerung - Eine Anwendungsdomäne für Organic Computing Konzepte
Prof. Dr. Jörg Hähner (Universität Augsburg)
 Der rasante Anstieg der Bevölkerung, vor allem in urbanen Gegenden, führt zu steigendem Verkehrsaufkommen von städtischen Verkehrsnetzen. Platzknappheit, als auch die hohen Kosten für den Ausbau der Verkehrsinfrastruktur führen dazu, dass der Bau von neuen Straßen oft keine Option darstellt diesem Problem entgegenzutreten. Deswegen sind neue Ansätze gefordert, die die bisherigen Strukturen besser ausnutzen.
Einen Ansatz stellt Organic Traffic Control (OTC) dar, der Konzepte des Organic Computing auf Straßennetze überträgt. Das OTC-System basiert auf einem selbst-organisierenden Observer/Controller-Framework, das die bestehenden Kreuzungscontroller um intelligente Algorithmen erweitert. Dieses bietet einen dezentralen Ansatz, basierend auf kommunizierenden Kreuzungscontrollern, die in der Lage sind, die Ampelschaltung zur Laufzeit selbstständig an die aktuelle Verkehrslage anzupassen. Des Weiteren werden autonom „Grüne Wellen“ über benachbarte Kreuzungen etabliert, um einen reibungslosen Verkehrsfluss durch das Netzwerk zu gewährleisten. Intelligente Routingverfahren zeigen Verkehrsteilnehmern über anpassbare Straßenschilder die schnellsten Wege durch das Netzwerk auf.
Aufbauend auf dem erfolgreichen OTC Projekt, schließt nun das Projekt „Resilient Traffic Management“ an. Weitergehende Schritte beinhalten u.a. die Implementierung von Mechanismen zur Vorhersage des Verkehrsaufkommens, als auch der Stauerkennung, sowie einer adaptiven Verkehrsführung zur Auflösung bestehender Stausituationen. Die Einbeziehung des öffentlichen Personennahverkehrs (ÖPNV) in die adaptive Ampelschaltung erlaubt es dem System z.B. Busse priorisiert zu behandeln.
Der rasante Anstieg der Bevölkerung, vor allem in urbanen Gegenden, führt zu steigendem Verkehrsaufkommen von städtischen Verkehrsnetzen. Platzknappheit, als auch die hohen Kosten für den Ausbau der Verkehrsinfrastruktur führen dazu, dass der Bau von neuen Straßen oft keine Option darstellt diesem Problem entgegenzutreten. Deswegen sind neue Ansätze gefordert, die die bisherigen Strukturen besser ausnutzen.
Einen Ansatz stellt Organic Traffic Control (OTC) dar, der Konzepte des Organic Computing auf Straßennetze überträgt. Das OTC-System basiert auf einem selbst-organisierenden Observer/Controller-Framework, das die bestehenden Kreuzungscontroller um intelligente Algorithmen erweitert. Dieses bietet einen dezentralen Ansatz, basierend auf kommunizierenden Kreuzungscontrollern, die in der Lage sind, die Ampelschaltung zur Laufzeit selbstständig an die aktuelle Verkehrslage anzupassen. Des Weiteren werden autonom „Grüne Wellen“ über benachbarte Kreuzungen etabliert, um einen reibungslosen Verkehrsfluss durch das Netzwerk zu gewährleisten. Intelligente Routingverfahren zeigen Verkehrsteilnehmern über anpassbare Straßenschilder die schnellsten Wege durch das Netzwerk auf.
Aufbauend auf dem erfolgreichen OTC Projekt, schließt nun das Projekt „Resilient Traffic Management“ an. Weitergehende Schritte beinhalten u.a. die Implementierung von Mechanismen zur Vorhersage des Verkehrsaufkommens, als auch der Stauerkennung, sowie einer adaptiven Verkehrsführung zur Auflösung bestehender Stausituationen. Die Einbeziehung des öffentlichen Personennahverkehrs (ÖPNV) in die adaptive Ampelschaltung erlaubt es dem System z.B. Busse priorisiert zu behandeln.
click here for the video version with slides
InvasIC Seminar, June 14, 2013 at FAU: Implementation of ISE for the micro-threaded model in LEON3 SPARC
Dr. Martin Danek

The talk will describe instruction set extensions for a variant of multi-threading called micro-threading for the LEON3 SPAR Cv8 processor. An architecture of the developed processor will be presented and its key blocks described – cache controller, register file, thread scheduler. The processor has been implemented in a Xilinx Virtex2Pro and Virtex5 FPGAs. The extensions will be evaluated in terms of extra resources needed, and the overall performance of the developed processor will be shown for a simple DSP computation typical for embedded systems.
InvasIC Seminar, May 24, 2013 at FAU: Using Synchronous Models for the Design of Parallel Embedded Systems
Prof. Dr. Klaus Schneider (University of Kaiserslautern)
 To meet required real-time constraints, modern embedded systems have to perform many tasks in parallel and therefore require the modeling of concurrent systems with an adequate notion of time. To this end, several models of computation (MoCs) have been defined that determine why (causality), when (time), which atomic action of the system is executed. The most important classes of MoCs are event-triggered, time/clock-triggered, and data-driven MoCs that have their on advantages and disadvantages.
This talk gives an overview on the design flow used in the Averest system developed at the University of Kaiserslautern. The heart of this design flow is a synchronous (clock-driven) MoC which is used for modeling, simulation, and formal verification. The use of a synchronous MoC offers many advantages for these early design phases. For the synthesis, however, it is for some target architectures difficult to maintain the synchronous MoC, and therefore transformations are applied to translate the original models into other MoCs. In particular, we consider transformations that allow developers to desynchronize the system into asynchronous components which is a new technique to synthesize distributed/multithreaded systems from verified synchronous models.
To meet required real-time constraints, modern embedded systems have to perform many tasks in parallel and therefore require the modeling of concurrent systems with an adequate notion of time. To this end, several models of computation (MoCs) have been defined that determine why (causality), when (time), which atomic action of the system is executed. The most important classes of MoCs are event-triggered, time/clock-triggered, and data-driven MoCs that have their on advantages and disadvantages.
This talk gives an overview on the design flow used in the Averest system developed at the University of Kaiserslautern. The heart of this design flow is a synchronous (clock-driven) MoC which is used for modeling, simulation, and formal verification. The use of a synchronous MoC offers many advantages for these early design phases. For the synthesis, however, it is for some target architectures difficult to maintain the synchronous MoC, and therefore transformations are applied to translate the original models into other MoCs. In particular, we consider transformations that allow developers to desynchronize the system into asynchronous components which is a new technique to synthesize distributed/multithreaded systems from verified synchronous models.
click here for the video version with slides
InvasIC Seminar, May 17, 2013 at FAU: Hardware and System Software Requirements for Multi-core Deployment in Hard Real-time Systems
Prof. Dr. Theo Ungerer (Universität Augsburg)
 Providing higher performance than state-of-the-art embedded processors can deliver today will increase safety, comfort, number and quality of services, while also lowering emissions as well as fuel demands for automotive, avionic and automation applications. Such a demand for increased computational performance is widespread among European key industries. Engineers who design hard real-time embedded systems in such embedded domains express a need for several times the performance available today while keeping safety as major criterion. A breakthrough in performance is expected by parallelising hard real-time applications and running them on an embedded multi-core processor, which enables combining the requirements for high-performance with time-predictable execution.
The talk will discuss results of the EC FP-7 project MERASA (Multi-Core Execution of Hard Real-Time Applications Supporting Analysability, 2007-2011) and objectives and preliminary results of the successor project parMERASA (Multi-Core Execution of Parallelised Hard Real-Time Applications Supporting Analysability, starting Oct. 1, 2011). Both projects target timing analysable systems of parallel hard real-time applications running on a scalable multi-core processor. MERASA delivered a fully timing analysable four-core SMT processor FPGA prototype together with adapted system software and WCET tools, running a parallelised version of a Honeywell International autonomous flying vehicle code as demonstrator. parMERASA shifts its objectives even more towards parallelisation of hard real-time software. To this end application companies of avionics, automotive, and construction machinery domains cooperate with tool developers and multi-core architects.
Providing higher performance than state-of-the-art embedded processors can deliver today will increase safety, comfort, number and quality of services, while also lowering emissions as well as fuel demands for automotive, avionic and automation applications. Such a demand for increased computational performance is widespread among European key industries. Engineers who design hard real-time embedded systems in such embedded domains express a need for several times the performance available today while keeping safety as major criterion. A breakthrough in performance is expected by parallelising hard real-time applications and running them on an embedded multi-core processor, which enables combining the requirements for high-performance with time-predictable execution.
The talk will discuss results of the EC FP-7 project MERASA (Multi-Core Execution of Hard Real-Time Applications Supporting Analysability, 2007-2011) and objectives and preliminary results of the successor project parMERASA (Multi-Core Execution of Parallelised Hard Real-Time Applications Supporting Analysability, starting Oct. 1, 2011). Both projects target timing analysable systems of parallel hard real-time applications running on a scalable multi-core processor. MERASA delivered a fully timing analysable four-core SMT processor FPGA prototype together with adapted system software and WCET tools, running a parallelised version of a Honeywell International autonomous flying vehicle code as demonstrator. parMERASA shifts its objectives even more towards parallelisation of hard real-time software. To this end application companies of avionics, automotive, and construction machinery domains cooperate with tool developers and multi-core architects.
click here for the video version with slides
InvasIC Seminar, April 26, 2013 at FAU: Timing Analysis for Real-Time Systems
Prof. Dr. Dr. h.c. Reinhard Wilhelm (Chair for Programming Languages and Compiler Construction, FR 6.2 Informatik, Universität des Saarlandes)
Prof. Wilhelm will give a lecture at this year's "Tag der Informatik" at FAU.
click here for the video version with slides
InvasIC Seminar, April 26, 2013 at FAU: A Short Story on Cyber-Physical Systems: From the Lab to Real-Life
Prof. Dr. Samarjit Chakraborty (Lehrstuhl für Realzeit-Computersysteme, Fakultät für Elektrotechnik und Informationstechnik, Technische Universität München)
Prof. Chakraborty will gave a lecture at this year's "Tag der Informatik" at FAU.
click here for the video version with slides
InvasIC Seminar, March 8, 2013 at FAU: Autonomie, Adaptivität, Selbstorganisation: Auf dem Weg zu Cyber Physical Systems
Prof. Franz-Josef Rammig (Heinz Nixdorf Institut, Universität Paderborn)
 Prof. Rammig gave the plenary lecture at the 10th anniversary of the Department of Computer Science 12 (Hardware-Software-Co-Design) at FAU.
Prof. Rammig gave the plenary lecture at the 10th anniversary of the Department of Computer Science 12 (Hardware-Software-Co-Design) at FAU.
click here for the video version with slides
InvasIC Seminar, February 26, 2013 at FAU: Energy Efficient Real-time Embedded Systems
Dr. Morteza Biglari-Abhari (Senior Lecturer at the Department of Electrical and Computer Engineering, University of Auckland)

Increase in the number of transistors following Moore’s Law enables designing more complex MPSoC for embedded applications. However, failure of Dennard’s scaling and increasing computational complexity of real-time applications demand new approaches to model and implement such complex embedded systems to achieve both the required performance and power/energy efficiency. Globally Asynchronous Locally Synchronous (GALS) systems are potentially suitable to cope with the optimization trade-offs to achieve both higher performance and lower power consumption. Optimizations can be more rewarding if they can be applied at the system level design. To support this, an appropriate system level modeling language is essential which can lead to both efficient capturing of the application characteristics as well as a fast pathway to its implementation. The other challenging and critical factor is to guarantee the worst case execution time (WCET) for hard real-time embedded systems and the worst case reaction time (WCRT) for reactive systems. SystemJ, which is a Java-based system level language extended with language constructs to support GALS model of computation has been developed to facilitate the system modeling and implementation of such embedded systems. However, using conventional implementation approaches such as JVM interpreter and JIT compilers not only cannot guarantee the WCRT but would impose a high performance overhead due to emulating the SystemJ language features. This work presents architectural supports for SystemJ application execution on embedded platforms and highlights the potential of achieving lower power consumption as well as execution time predictability.
click here for the video version with slides
Events 2012
InvasIC Seminar, Friday, November 30, 2012 at FAU: Design and Analysis for Timing Critical Systems
Prof. Dr. Jian-Jia Chen (Juniorprofessor in the Department of Informatics at KIT)
 Real-time systems play a crucial role in many applications, such as avionic control systems, automotive electronics, telecommunications, industrial automation, and robotics. Such safety-critical applications require high reliability in timing assurance to prevent from serious damage to the environment and significant human loss. For decades, designing scheduling policies and analyzing the worst-case timing behavior have been extensively studied, from periodic tasks, to sporadic tasks, and even to tasks with irregular arrival curves. In this talk, I will present the recent researches on design and analysis for timing critical systems by covering the approximate schedulability analysis, design and analysis for resource reservation servers, and multicore/multiprocessor systems with resource sharing.
Real-time systems play a crucial role in many applications, such as avionic control systems, automotive electronics, telecommunications, industrial automation, and robotics. Such safety-critical applications require high reliability in timing assurance to prevent from serious damage to the environment and significant human loss. For decades, designing scheduling policies and analyzing the worst-case timing behavior have been extensively studied, from periodic tasks, to sporadic tasks, and even to tasks with irregular arrival curves. In this talk, I will present the recent researches on design and analysis for timing critical systems by covering the approximate schedulability analysis, design and analysis for resource reservation servers, and multicore/multiprocessor systems with resource sharing.
InvasIC Seminar, Wednesday, November 28, 2012 at TUM: Modelling of microscopic flows using particle-based methods
Severin Strobl (Institute for Multiscale Simulation, FAU)
We employ a simulation framework which is based entirely on particle and quasi-particle methods for the simulation of flows of microscopic suspensions through micro-fluidic devices. The solvent phase is modelled using Direct Simulation Monte Carlo (DSMC), while Molecular Dynamics (MD) is used for the suspended particles. Micro-fluidic devices are difficult to simulate as the geometry of these devices is often complex and tortuous. The small scale of the flows also makes it essential that the interactions of the boundaries with the fluid and suspended particles are accurately described. Effects such as the non-Maxwellian velocity distribution of the fluid particles near boundaries must be captured as these become dominant effects at small scales, in particular for confined geometries. Both these complex geometry and boundary difficulties can be tackled using particle-based methods. Almost arbitrary geometries can be handled by our DSMC code and the boundary regions can be treated using interaction rules derived from molecular theories. While the applied particle methods provide a very high physical accuracy, they also impart a significant numerical cost. For the case of arbitrary geometries, special care must be taken to ensure an efficient implementation of the methods. Here, a main focus is the performance optimization for shared-memory NUMA systems.
InvasIC Seminar, Tuesday, November 27, 2012 at TUM: Jens Zudrop and Simon Zimny (German Research School for Simulation Sciences, Aachen)
Jens Zudrop: Massively parallel simulations on Octree based meshes
The Spectral Discontinuous Galerkin method on Octrees: During the last decade numerical simulation techniques evolved from mathematical playgrounds to practical tools for scientist and engineers. Clearly, this evolution is also a consequence of increasing computational power. However, it can be observed that in the last years the rise in compute power is due to growing parallelism. Necessarily, the numerical simulation tools have to be suited well for these massively parallel simulation settings. Most of the numerical methods are based on a triangulation of the simulation domain and the numerical solver uses basic mesh operations like neighbor lookup. On very large systems with more than 100 thousand cores already such a simple mesh operation can be very time consuming. In the first part of the talk we present an Octree based mesh framework that circumvents these problems and allows for a fully parallel mesh setup with a minimum amount of synchronization. In our approach, we linearize the Octree based mesh by a space filling curve and decompose the domain by means of this linearized element list. By this approach, mesh operations like neighbor lookup become completely local. We show that the framework is able to scale up to complete, state of the art HPC systems and achieves a very high efficiency. In the second part of the presentation we focus on numerical methods based on our Octree framework. The Discontinuous Galerkin method is a very prominent example of such techniques, which works well for hyper- bolic conservation laws. One of the strengths of this numerical scheme is its ability to achieve high orders and to deal with non-conforming element refinement. Furthermore, we use the equations of electrodynamics and inviscid, compressible fluid flow as examples for linear and nonlinear conservation laws and discuss implementation aspects with respect to them. Finally, we present the scalability and performance results of such a solver on state of the art HPC systems.
Simon Zimny: Efficiency and scalability on SuperMUC: Lattice Boltzmann Methods on complex geometries
Simulating blood flow in patient specific intracranial aneurysms: The Lattice Boltzmann Method (LBM) is a promising alternative to the classical approaches of solving the Navier-Stokes equations numerically. Due to its explicit and local nature it is highly suitable for massive parallization and by this also on simulating fluid flows in extremly complex geometries like the blood flow. In recent years the treatment process of intracranial aneurysms (IA) has been studied at length and increased significantly . The use of stents to change the flow properties of the blood in order to trigger the occlusion of IA is a promising way. As a prerequisite for implementing a coupled simulation for thrombus formation in IA, the flow of blood and especially the change of flow patterns due to the insertion of one or multiple stent(s) has to be analysed in detail. In order to resolve the highly complex geometry of IA and individual struts of a stent in detail, the mesh resolution has to be sufficiently high, resulting in a huge number of elements (in the order of 107 − 109 ). Simulating the blood flow in geometries like these in a reasonable time requires large computational power. Although an efficiently parallizable numerical method like the LBM including techniques like local grid refinement are dedicated to reduce the computational power tremendously, the use of HPC-systems, like the superMUC, is still necessary. The Adaptable Poly-Engineering Simulator (Apes) framework provides the full toolchain from the mesh creation (Seeder) over the blood flow simulations using the LBM (Musubi) to the postprocessing (Harvester). The LBM solver, Musubi, is highly efficient and scalable up to more than 100 thousand cores and by this optimal for fluid flow simulations in complex geometries. The talk will be split up in two parts. At first the Musubi solver is introduced in the context of the Apes simulation framework including implemented techniques like local grid refinement and other features. After this the performance of the Musubi code on the superMUC will be discussed based on a simple testcase and a full 3D simulation of flow through highly complex patient specific geometries like an IA as described.
InvasIC Seminar, Tuesday, November 20, 2012 at FAU: Building Future Embedded Systems – Internet of Things and Beyond
Prof. Zoran Salcic (Department of Electrical and Computer Engineering at the University of Auckland, New Zealand)
Computing applications are increasingly characterized by their direct interaction with physical world using sensors and actuators, distributed processing and communication via various kinds of networks, Internet connectivity and addressability, as well as the communication with humans via traditional computers and different mobile platforms. These systems are pervasive by their nature and incorporate Internet addressable and reachable smart elements, called Things, which in turn create Internet of Things. Internet of Things will enable creation of such new types of systems and applications. While elements of such systems have been explored and understood rather well by experts and researchers in computer engineering community, methods to build large systems that integrate multiple of aforementioned technologies and large number of Things are still in their very early stage. System design methods, which go beyond traditional programming, are needed and are the only way to go ahead in creation of systems based on Internet of Things. In this seminar we will address some major involved technologies and give examples how large systems can be created using integrated design approach. New design paradigm that enables creation of systems based on Globally Asynchronous Locally Synchronous (GALS) model of computation accompanied with system-level design and programming language that abstracts the physical world, on one hand, and distributed heterogeneous computing platforms that incorporates Internet addressable elements, on the other hand, enable creation of new classes of embedded systems that address the needs of future smart grid, building automation, farming, transportation and other complex systems. Some of the challenges, research directions and possible ways to address them will also be presented.
InvasIC Seminar, Friday, October 19, 2012 at FAU: Large Scale Multiprocessing: From SoCs to Supercomputers.
Souradip Sarkar (Intel Exascience labs, Ghent University)
 The focus of the talk will be primarily on design and performance evaluation of a custom Network on Chip (NoC) based multi-core hardware accelerator for computational biology. Numerous pervasive scientific applications are the catalysts driving the Architecture, Systems, Circuits and Devices research. The scalability of the design approach targeting a specific application and design of the infrastructure for addressing the next generation applications poses the several challenges. Our work is a step in this direction.The second part of the talk will touch upon a simulation framework meant to provide early design stage hardware-software codesign and co-optimization from the power and thermal management perspective.
The focus of the talk will be primarily on design and performance evaluation of a custom Network on Chip (NoC) based multi-core hardware accelerator for computational biology. Numerous pervasive scientific applications are the catalysts driving the Architecture, Systems, Circuits and Devices research. The scalability of the design approach targeting a specific application and design of the infrastructure for addressing the next generation applications poses the several challenges. Our work is a step in this direction.The second part of the talk will touch upon a simulation framework meant to provide early design stage hardware-software codesign and co-optimization from the power and thermal management perspective.
click here for the video version with slides
InvasIC Seminar, Friday, September 14, 2012 at FAU: Embedded Multicore Design Technologies: The Next Generation
Prof. Dr. rer. nat. Rainer Leupers (Institute for Communication Technologies and Embedded Systems, RWTH Aachen University)
 Due to power and performance reasons, MPSoC architectures are getting
widespread in virtually all domains of computing. Their HW/SW design
constraints are particularly tight in wireless communication devices.
The amount of mobile data traffic
is expected to grow by 1000x within the next decade, resulting in very high
performance requirements. At the same time, especially in battery driven
devices, maximum energy efficiency is a must.
Moreover, the problem of how to efficiently implement software on embedded
parallel processor architectures is largely unsolved today. This keynote
covers several novel system-level design technologies, conceived to help in
efficient HW/SW design for multi-billion transistor embedded multicore
platforms, with emphasis on the special demands of wireless applications.
We will provide an introduction
to automated design of application specific processors as the key MPSoC
building blocks.
Next, we will discuss some recent advances in virtual prototyping and
high-speed simulation of complex architectures and entire devices.
Furthermore, we will sketch the MAPS compiler approach for mapping embedded
application software onto heterogeneous parallel target platforms. Finally,
we provide an outlook on further key research issues in embedded systems
design to support the the future "mobile society".
Due to power and performance reasons, MPSoC architectures are getting
widespread in virtually all domains of computing. Their HW/SW design
constraints are particularly tight in wireless communication devices.
The amount of mobile data traffic
is expected to grow by 1000x within the next decade, resulting in very high
performance requirements. At the same time, especially in battery driven
devices, maximum energy efficiency is a must.
Moreover, the problem of how to efficiently implement software on embedded
parallel processor architectures is largely unsolved today. This keynote
covers several novel system-level design technologies, conceived to help in
efficient HW/SW design for multi-billion transistor embedded multicore
platforms, with emphasis on the special demands of wireless applications.
We will provide an introduction
to automated design of application specific processors as the key MPSoC
building blocks.
Next, we will discuss some recent advances in virtual prototyping and
high-speed simulation of complex architectures and entire devices.
Furthermore, we will sketch the MAPS compiler approach for mapping embedded
application software onto heterogeneous parallel target platforms. Finally,
we provide an outlook on further key research issues in embedded systems
design to support the the future "mobile society".
InvasIC Seminar, Wed, July 25, 2012, 01:30 pm at FAU: Organic Computing – Quo vadis?
Prof. Dr.-Ing. C. Müller-Schloer (Institut für Systems Engineering - System- und RechnerArchitektur (SRA) Leibniz Universität Hannover)
 Organic Computing has emerged almost 10 years ago as a challenging vision for future information
processing systems, based on the insight that already in the near future we will be
surrounded by large collections of autonomous systems equipped with sensors and actuators
to be aware of their environment, to communicate freely, and to organize themselves.
The presence of networks of intelligent systems in our environment opens fascinating application
areas but, at the same time, bears the problem of their controllability. Hence, we have
to construct these systems - which we increasingly depend on - as robust, safe, flexible, and
trustworthy as possible. In particular, a strong orientation of these systems towards human
needs as opposed to a pure implementation of the technologically possible seems absolutely
central. In order to achieve these goals, our technical systems will have to act more independently,
flexibly, and autonomously, i.e. they will have to exhibit life-like properties. We call
those systems “organic”. Hence, an “Organic Computing System” is a technical system,
which adapts dynamically to the current conditions of its environment. It will be selforganizing,
self-configuring, self-healing, self-protecting, self-explaining, and context-aware.
First steps towards adaptive and self-organizing computer systems are already being undertaken.
Adaptivity, reconfigurability, emergence of new properties, and self-organisation are
topics in a variety of research projects. From 2005 until 2011 the German Science Foundation
(DFG) has funded a priority research program on Organic Computing. It addresses fundamental
challenges in the design of complex computing systems; its objective is a deeper
understanding of emergent global behaviour in self-organising systems and the design of
specific concepts and tools to support the construction of Organic Computing systems for
technical applications. With the upcoming conclusion of the priority program in September
2011, we have to start the discussion about the future of OC: Organic Computing – Quo vadis?
This presentation will briefly recapitulate the research ideas of Organic Computing, explain
key concepts, and illustrate these concepts with current technical application projects from
the priority program. Before future directions can be discussed we will look at the lessons
learnt so far. From this, we will derive important trends in OC, which can serve as guidelines
for future research. These trends can be subsumed as (1) Design-time to run-time and (2)
Social OC. Finally the talk will raise some mission-critical questions, which we will have to
answer in due time if the vision of Organic Computing is to be fulfilled.
Organic Computing has emerged almost 10 years ago as a challenging vision for future information
processing systems, based on the insight that already in the near future we will be
surrounded by large collections of autonomous systems equipped with sensors and actuators
to be aware of their environment, to communicate freely, and to organize themselves.
The presence of networks of intelligent systems in our environment opens fascinating application
areas but, at the same time, bears the problem of their controllability. Hence, we have
to construct these systems - which we increasingly depend on - as robust, safe, flexible, and
trustworthy as possible. In particular, a strong orientation of these systems towards human
needs as opposed to a pure implementation of the technologically possible seems absolutely
central. In order to achieve these goals, our technical systems will have to act more independently,
flexibly, and autonomously, i.e. they will have to exhibit life-like properties. We call
those systems “organic”. Hence, an “Organic Computing System” is a technical system,
which adapts dynamically to the current conditions of its environment. It will be selforganizing,
self-configuring, self-healing, self-protecting, self-explaining, and context-aware.
First steps towards adaptive and self-organizing computer systems are already being undertaken.
Adaptivity, reconfigurability, emergence of new properties, and self-organisation are
topics in a variety of research projects. From 2005 until 2011 the German Science Foundation
(DFG) has funded a priority research program on Organic Computing. It addresses fundamental
challenges in the design of complex computing systems; its objective is a deeper
understanding of emergent global behaviour in self-organising systems and the design of
specific concepts and tools to support the construction of Organic Computing systems for
technical applications. With the upcoming conclusion of the priority program in September
2011, we have to start the discussion about the future of OC: Organic Computing – Quo vadis?
This presentation will briefly recapitulate the research ideas of Organic Computing, explain
key concepts, and illustrate these concepts with current technical application projects from
the priority program. Before future directions can be discussed we will look at the lessons
learnt so far. From this, we will derive important trends in OC, which can serve as guidelines
for future research. These trends can be subsumed as (1) Design-time to run-time and (2)
Social OC. Finally the talk will raise some mission-critical questions, which we will have to
answer in due time if the vision of Organic Computing is to be fulfilled.
click here for the video version with slides
InvasIC Seminar, Fri, July 6, 2012, 11:00 am at FAU: When does it get hot?
Prof. Dr. Lothar Thiele (Head of the Department Information Technology and Electrical Engineering, ETH Zurich)
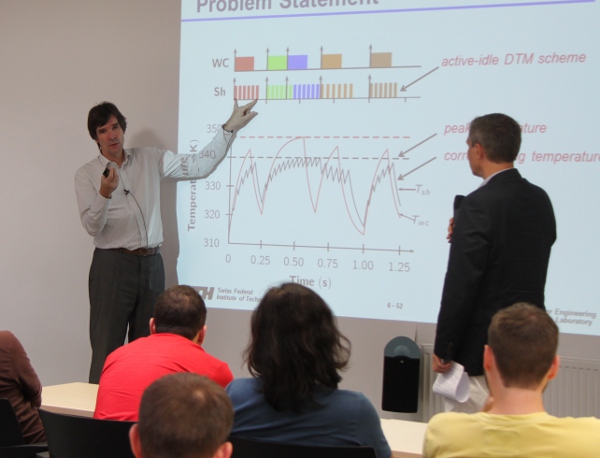 With the evolution of today's semiconductor technology,
chip temperature increases rapidly mainly due to the growth
in power density. However, the obtained increase in
performance imposes a major increase in temperature, which
in turn reduces the system reliability. Exceeding a certain
threshold temperature could lead to a reduction of
performance, or even the damage of the physical system.
The presentation will describe models and methods that link
the discrete world of computations with temperature. This allows
to answer some fundamental questions like: What is the maximal
temperature during a computation? What timing properties can be
guaranteed under feedback control of temperatures?
In addition, we will show how the temperature constraint can be
integrated into a high-level programming environment for
embedded multiprocessor systems.
With the evolution of today's semiconductor technology,
chip temperature increases rapidly mainly due to the growth
in power density. However, the obtained increase in
performance imposes a major increase in temperature, which
in turn reduces the system reliability. Exceeding a certain
threshold temperature could lead to a reduction of
performance, or even the damage of the physical system.
The presentation will describe models and methods that link
the discrete world of computations with temperature. This allows
to answer some fundamental questions like: What is the maximal
temperature during a computation? What timing properties can be
guaranteed under feedback control of temperatures?
In addition, we will show how the temperature constraint can be
integrated into a high-level programming environment for
embedded multiprocessor systems.
click here for the video version with slides
InvasIC Seminar, Fri, June 29, 2012, 9:00 am at FAU: Application-driven Embedded System Design
Prof. Dr. Antônio Augusto Fröhlich (Associate Prof. of Operating Systems at the Federal University of Santa Catarina UFSC / Head the Software/Integration Lab LISHA)
Application-driven Embedded System Development (ADESD) defines a strategy to design and implement embedded systems as aggregates of reusable components arranged in application-specific frameworks. ADESD addresses the gap between the two most promising methodologies in the field, Model-driven Engineering and Platform-based Design, by offering concrete alternatives to translate Platform-independent Models into Platform-specific Models, and also by promoting beyond-platform reuse. While guiding the development of reusable (hardware, software, or hybrid) components that encapsulate scenario- independent abstractions, ADESD induces scenario dependencies to be modeled as Aspect programs. Resulting components can thus be automatically woven to a variety of execution scenarios by meas of Scenario Adapters. Scenarios themselves are modeled as application-specific component frameworks. ADESD main test case, the EPOS system, has been ported to a dozen distinct architectures, including AVR, H8, ARM, MIPS, SPARC, PowerPC, and x86, and has been deployed in scenarios as distinct as scientific computing in super computers and sensor networks, therefore confirming the reusability of components.
InvasIC Seminar, Fri, June 29, 2012, 10:30 am at FAU: Software System Engineering: Was fehlt noch?
David Lorge Parnas
The recognition that software had to be constructed in the disciplined and science-based way that other products are constructed began with the study of operating systems. The first operating systems were simple programs designed to replace the computer operator. Soon they took responsibility for other tasks such as permitting simultaneous execution of several user jobs at once and managing shared resources. They became the most complex programs in widespread use. The problems that were first encountered in operating systems are now present in many other software products. Ideas that were pioneered in operating systems are now commonly used in those products. Thanks to advances in hardware and software, computers can perform services that were unimaginable when we started. However, many problems remain. Software products commonly have a number of “bugs” and other problems that we would not accept in a car or an elevator. Things essential in a mature profession are missing.This talk discusses three of them, viz:
- Education that prepares developers to apply, science, education, and discipline to software taskz.
- Rigid entrance standards for the profession.
- Professional documentation standards similar to those used in other engineering disciplines.
The least discussed of the three is documentation. The talk shows how we can use structured mathematical notation to provide precise documentation that is complete and useful to developers, reviewers, and maintainers.
InvasIC Seminar, Fri, June 22, 2012, 11:00 am at FAU: Programmability and Performance Portability for Heterogeneous Many-Core Systems
Prof. Dr. Siegfried Benkner (Research Group Scientific Computing, University of Vienna)
 With the shift towards heterogeneous many-core architectures the challenges of parallel programming will sharply rise. To cope with the complexity of programming such architectures, research in higher-level parallel programming models and advanced compilation and runtime technology will be crucial. In this talk we report on research efforts towards programming support for heterogeneous many-core architectures as currently pursued within the EU project PEPPHER. PEPPHER proposes a compositional approach to parallel software development, with support for different programming models, associated compilation techniques, a library of adaptive algorithms and lock-free data structures, and advanced runtime scheduling mechanisms. The major goal of PEPPHER is to enhance programmability of future parallel systems, while ensuring efficiency and performance portability across a range of different architectures. PEPPHER bases its developments upon a high-level task-based programming model, where tasks correspond to multi-architectural, resource-aware components encapsulating different implementation variants of performance-critical application functionality tailored for different hardware resources. A sophisticated runtime system is utilized to select and dynamically schedule component implementation variants for efficient parallel execution on heterogeneous many-core architectures. Experimental results indicate that with our high-level approach performance comparable to manual parallelization can be achieved while significantly improving programmability and portability.
PDF-Slides
With the shift towards heterogeneous many-core architectures the challenges of parallel programming will sharply rise. To cope with the complexity of programming such architectures, research in higher-level parallel programming models and advanced compilation and runtime technology will be crucial. In this talk we report on research efforts towards programming support for heterogeneous many-core architectures as currently pursued within the EU project PEPPHER. PEPPHER proposes a compositional approach to parallel software development, with support for different programming models, associated compilation techniques, a library of adaptive algorithms and lock-free data structures, and advanced runtime scheduling mechanisms. The major goal of PEPPHER is to enhance programmability of future parallel systems, while ensuring efficiency and performance portability across a range of different architectures. PEPPHER bases its developments upon a high-level task-based programming model, where tasks correspond to multi-architectural, resource-aware components encapsulating different implementation variants of performance-critical application functionality tailored for different hardware resources. A sophisticated runtime system is utilized to select and dynamically schedule component implementation variants for efficient parallel execution on heterogeneous many-core architectures. Experimental results indicate that with our high-level approach performance comparable to manual parallelization can be achieved while significantly improving programmability and portability.
PDF-Slides
click here for the video version with slides
InvasIC Seminar, Thu, May 24, 2012, 2 pm at FAU: Robust System Design
Prof. Subhasish Mitra (Department of Electrical Engineering and Department of Computer Science, Stanford University, USA)
 Today’s mainstream electronic systems typically assume that
transistors and interconnects operate correctly over their useful
lifetime. With enormous complexity and significantly increased
vulnerability to failures compared to the past, future system designs
cannot rely on such assumptions. At the same time, there is explosive
growth in our dependency on such systems.
Robust system design is essential to ensure that future systems
perform correctly despite rising complexity and increasing
disturbances. For coming generations of silicon technologies, several
causes of hardware failures, largely benign in the past, are becoming
significant at the system-level. Furthermore, emerging
nanotechnologies such as carbon nanotubes are inherently highly
subject to imperfections.
With extreme miniaturization of circuits, factors such as transient
errors, device degradation, and variability induced by manufacturing
and operating conditions are becoming important. While design margins
are being squeezed to achieve high energy efficiency, expanded design
margins are required to cope with variability and transistor aging.
Even if error rates stay constant on a per-bit basis, total chip-level
error rates grow with the scale of integration. Moreover, difficulties
with traditional burn-in can leave early-life failures unscreened.
Today’s mainstream electronic systems typically assume that
transistors and interconnects operate correctly over their useful
lifetime. With enormous complexity and significantly increased
vulnerability to failures compared to the past, future system designs
cannot rely on such assumptions. At the same time, there is explosive
growth in our dependency on such systems.
Robust system design is essential to ensure that future systems
perform correctly despite rising complexity and increasing
disturbances. For coming generations of silicon technologies, several
causes of hardware failures, largely benign in the past, are becoming
significant at the system-level. Furthermore, emerging
nanotechnologies such as carbon nanotubes are inherently highly
subject to imperfections.
With extreme miniaturization of circuits, factors such as transient
errors, device degradation, and variability induced by manufacturing
and operating conditions are becoming important. While design margins
are being squeezed to achieve high energy efficiency, expanded design
margins are required to cope with variability and transistor aging.
Even if error rates stay constant on a per-bit basis, total chip-level
error rates grow with the scale of integration. Moreover, difficulties
with traditional burn-in can leave early-life failures unscreened.
This talk will address the following major robust system design goals:
- New approaches to thorough test and validation that scale with tremendous growth in complexity.
- Cost-effective tolerance and prediction of failures in hardware during system operation.
- A practical way to overcome substantial inherent imperfections in emerging nanotechnologies.
Significant recent progress in robust system design impacts almost every aspect of future systems, from ultra-large-scale networked systems, all the way to their nanoscale components.
click here for the video version with slides
InvasIC Seminar, Mo, May 21, 2012, 1 pm at FAU: HOPES: A Model-Based Design Framework of Parallel Embedded Systems
Soonhoi Ha (Computer Engineering Department. Seoul National University)
 In this talk, I will introduce a novel model-based design framework, called HOPES, of parallel embedded systems, targetting from MPSoC to distributed embedded systems. In particular, we focus on parallel embedded SW design, which becomes more challenging than hardware design as the system complexity grows. Parallel embedded software design is a parallel programming for non-trivial heterogeneous multi-processors with diverse communication architectures and design constraints such as hardware cost, power, and timeliness. In the language-based approach of parallel programming, e.g. openMP and OpenCL, the programmer should manually optimize the parallel code for a given target architecture without any aid to verify the satisfaction of the design constraints beforehand. On the other hand, model-based design separates specification from implementation. Various models have been proposed depending on the application domain with different characteritics. Since software synthesis is a refinement procedure from a model, the model affects the style and the performance of the synthesized software. In HOPES, we propose a new model-based design approach based on a novel actor model called Common Intermediate Code (CIC). It is not only an initial specification model but an execution model of the target architecture; we call it as a “programming platform”. In CIC, three types of actors are specified: function, control, and library actors. The CIC translator translates the CIC into the final parallel code considering the target architecture and the design constraints, to make the CIC retargetable. Design validation is performed by static analysis and parallel co-simulation of hardware and software. In this talk, I will overview the key research subjects involved in the HOPES design flow and some research results we have achieved so far.
In this talk, I will introduce a novel model-based design framework, called HOPES, of parallel embedded systems, targetting from MPSoC to distributed embedded systems. In particular, we focus on parallel embedded SW design, which becomes more challenging than hardware design as the system complexity grows. Parallel embedded software design is a parallel programming for non-trivial heterogeneous multi-processors with diverse communication architectures and design constraints such as hardware cost, power, and timeliness. In the language-based approach of parallel programming, e.g. openMP and OpenCL, the programmer should manually optimize the parallel code for a given target architecture without any aid to verify the satisfaction of the design constraints beforehand. On the other hand, model-based design separates specification from implementation. Various models have been proposed depending on the application domain with different characteritics. Since software synthesis is a refinement procedure from a model, the model affects the style and the performance of the synthesized software. In HOPES, we propose a new model-based design approach based on a novel actor model called Common Intermediate Code (CIC). It is not only an initial specification model but an execution model of the target architecture; we call it as a “programming platform”. In CIC, three types of actors are specified: function, control, and library actors. The CIC translator translates the CIC into the final parallel code considering the target architecture and the design constraints, to make the CIC retargetable. Design validation is performed by static analysis and parallel co-simulation of hardware and software. In this talk, I will overview the key research subjects involved in the HOPES design flow and some research results we have achieved so far.
click here for the video version with slides
InvasIC Seminar, Fri, May 18, 2012, 2 pm at FAU: Kernel Offloading for FPGA with Optimized Remote Accesses
Alain Darte (Directeur de recherche au CNRS. Laboratoire de l'Informatique du Parallélisme)
 Some data- and compute-intensive applications can be accelerated by
offloading portions of codes to platforms such as GPGPUs or FPGAs.
However, to get high performance for these kernels, it is mandatory to
restructure the application, to generate adequate communication
mechanisms for the transfer of remote data, and to make good usage of
the memory bandwidth. In the context of the high-level synthesis (HLS),
from a C program, of hardware accelerators on FPGA, we show how to
automatically generate optimized remote accesses for an accelerator
communicating to an external DDR memory. Loop tiling is used to enable
block communications, suitable for DDR memories. Pipelined
communication processes are generated to overlap communications and
computations, thereby hiding some latencies, in a way similar to double
buffering. Finally, data reuse among tiles is exploited to avoid remote
accesses when data are already available in the local memory.
Some data- and compute-intensive applications can be accelerated by
offloading portions of codes to platforms such as GPGPUs or FPGAs.
However, to get high performance for these kernels, it is mandatory to
restructure the application, to generate adequate communication
mechanisms for the transfer of remote data, and to make good usage of
the memory bandwidth. In the context of the high-level synthesis (HLS),
from a C program, of hardware accelerators on FPGA, we show how to
automatically generate optimized remote accesses for an accelerator
communicating to an external DDR memory. Loop tiling is used to enable
block communications, suitable for DDR memories. Pipelined
communication processes are generated to overlap communications and
computations, thereby hiding some latencies, in a way similar to double
buffering. Finally, data reuse among tiles is exploited to avoid remote
accesses when data are already available in the local memory.
One of our primary goals was to be able to express such an optimized code generation scheme, entirely at source-level, i.e., in C. This way, we can compile the computation kernel and all the necessary glue (the communication processes) with the same HLS tool, with no additional interfacing VHDL code. In other words, we can use the HLS tool (in our case, Altera C2H) as a back-end compiler. In terms of code analysis, code optimizations, and code transformations, our techniques rely on advanced parametric polyhedral techniques. An important step is to be able to specify the sets of data to be read from (resp. written to) the external memory just before (resp. after) each tile so as to reduce communications and reuse data as much as possible in the accelerator. The main difficulty arises when some data may be (re)defined in the accelerator and, even worse, in the case of approximations, when some data may be redefined but not for sure. Finally, combining coarse-grain software pipelining and lattice-based memory allocation, we can also automatically design the required local memories to store these data.
click here for the video version with slides
InvasIC Seminar: Fri, April 20, 2012, 4:15 pm at FAU: Expanding the Envelope – European Intel Research in Visual Computing, Exascale and Parallelism
Hans-Christian Hoppe (Director ExaCluster Lab, Jülich)
 Hans-Christian Hoppe will give a talk at the Tag der Informatik at the FAU in Erlangen.
Hans-Christian Hoppe will give a talk at the Tag der Informatik at the FAU in Erlangen.
Intel betreibt weltweit Forschung und Entwicklung in vielfältigen Gebieten der Computer- und Softwaretechnik. Das Netzwerk der „Intel Labs Europe“ alleine umfasst 30 Labs mit einer großen Bandbreite an Themen von Prozessentwicklung und Hardwarearchitektur über grundlegende Softwarefragen bis hin zu Computergrafik, Exascale Computing und Energieeffizienz. Der Vortrag gibt einen Einblick in aktuelle Projekte im Bereich Visual Computing, Parallelverarbeitung und High Performance Computing.
InvasIC Seminar, April 04, 2012 at TUM: New and old Features in MPI-3.0: The Past, the Standard, and the Future
Dr. Torsten Hoefler (University of Illinois at Urbana-Champaign)
The Message Passing Interface (MPI) became the de-facto standard for large-scale parallel programming since MPI-1 was ratified nearly two decades ago. Shortly after, MPI-1 was extended, adding support for I/O and One-Sided (RMA) operations in MPI-2. Ten years later, the Forum reconvened to discuss further extensions to MPI. MPI-2.2 was released in 2008 with mostly bugfixes but also a significant enhancement to the topology chapter which enables scalable MPI process mapping. The Forum is now working towards MPI-3.0 which is in its final stages. This talk will discuss new key features of MPI-3.0 and their anticipated use and benefit. We will discuss the user's, the implementer's, and sometimes the "standardese" perspective on the proposed features. The list includes nonblocking and neighborhood collectives, matched probe, the new One Sided operations and semantics including shared memory windows, and new communicator creation functions in depth.
InvasIC Seminar, Fri, Feb. 17, 2012 at FAU: Efficiency Metrics and Bandwidth - A Memory Perspective
Prof. Dr.-Ing. Norbert Wehn (Microelectronic Systems Design Research Group, University of Kaiserslautern)
 The race for increasing computing performance implied a dramatic increase in power which represents the main wall for further increase in computing. The "multi-core revolution" has shown a way out. Thus, today's state-of-the-art architectures in embedded computing are based on heterogeneous multi-core architectures with application specific optimized accelerators. Unfortunately the immense computing power of such multi-core architectures brings as negative effect an increased demand on bandwidth and memory, denoted as bandwidth and memory walls. In this talk we will discuss two topics strongly related to the memory and bandwidth wall. First, the impact of memories and data transfers on metrics to compare different algorithms and implementations in the context of wireless baseband processing architectures. Second, the design space and potential of 3D DRAM architectures and multi-channel DRAM controllers.
PDF-Slides
The race for increasing computing performance implied a dramatic increase in power which represents the main wall for further increase in computing. The "multi-core revolution" has shown a way out. Thus, today's state-of-the-art architectures in embedded computing are based on heterogeneous multi-core architectures with application specific optimized accelerators. Unfortunately the immense computing power of such multi-core architectures brings as negative effect an increased demand on bandwidth and memory, denoted as bandwidth and memory walls. In this talk we will discuss two topics strongly related to the memory and bandwidth wall. First, the impact of memories and data transfers on metrics to compare different algorithms and implementations in the context of wireless baseband processing architectures. Second, the design space and potential of 3D DRAM architectures and multi-channel DRAM controllers.
PDF-Slides
click here for the video version with slides
InvasIC Seminar, Feb. 10, 2012 at FAU Kernfragen: Multicore-Prozessoren in der Industrie
Urs Gleim (Siemens AG, Corporate Technology, Munich)
 Urs Gleim, Leiter des Parallel Processing Systems Teams bei der zentralen Forschung der Siemens AG (Corporate Technology), diskutiert in diesem Vortrag die technischen Herausforderungen der nächsten Jahre aus industrieller Sicht. Der Schwerpunkt der Betrachtung liegt auf der Nutzung neuer, insbesondere paralleler, Hardwarearchitekturen. Abschlie&suml;end stellt er ausgewählte aktuelle Arbeiten von Siemens in diesem Umfeld vor.
PDF-Slides
Urs Gleim, Leiter des Parallel Processing Systems Teams bei der zentralen Forschung der Siemens AG (Corporate Technology), diskutiert in diesem Vortrag die technischen Herausforderungen der nächsten Jahre aus industrieller Sicht. Der Schwerpunkt der Betrachtung liegt auf der Nutzung neuer, insbesondere paralleler, Hardwarearchitekturen. Abschlie&suml;end stellt er ausgewählte aktuelle Arbeiten von Siemens in diesem Umfeld vor.
PDF-Slides
click here for the video version with slides
InvasIC Seminar, Feb. 9, 2012 at TUM Friends Don't Let Friends Tune Code
Dr. Jeff Hollingsworth, (University of Maryland)
Tuning code for a specific system has often been necessary, but rarely enjoyable or easy. With many variants of a given architecture now being used in machines, for example the many implementations of the x86 instruction set, tuning has become even more difficult. In this talk, I will outline our work on the Active Harmony Auto-tuning system. I will present some results showing that we can improve the performance of real codes, and that the best configuration can vary quite a bit even among very similar CPUs. Our tool is capable of both online (tuning for a single execution) and offline (tuning using training runs) operation. I will also describe our core search algorithm, Parallel Rank Order.
Events 2011
- Guest at KIT: Prof. Alejandro Lopez-Ortiz Prof. Alejandro Lopez-Ortiz (http://www.cs.uwaterloo.ca/~alopez-o/) visited the Institut für Theoretische Informatik (Prof. Sanders) at the KIT from October 24 - November 17 2011 Prof. Lopez-Ortiz is an expert in the fields of System Modelling and Online-Algorithms, especially for Caching Problems.
- Guest at TUM: Dr. Gilles Fourestey Dr. Gilles Fourestey from the Swiss National Supercomputing Centre (Lugano) visited the Chair of Scientific Computing (Prof. Bungartz) at TUM in November 2011.
InvasIC Seminar, November 18, 2011 at TUM:
Parallelization of the Computation of a SPAI Preconditioner.
Dr. Gilles Fourestey (Swiss National Supercomputing Centre, Lugano)
Abstract: Because of their arithmetic intensity and inherent data structures, sparse linear algebra algorithms (and in particular finite element preconditioners computation) are very difficult to scale on HPC cluster beyond 1.000 MPI processes and can only reach a few percent of their theoretical peak performance. If we follow the current trend, exascale clusters will likely pack CPU nodes with hundreds of cores (compared to 16 today) and some kind of SIMD accelerators, making sparse linear algebra algorithms even harder to scale. Sparse inverse approximations, thanks to heir highly parallel profiles, may be excellent finite element precondtioners candidates that will keep up with future HPC systems. Especially the SPAI preconditioner has to be computed in a dynamic and adaptive way, demanding for different types (GPUs/CPUs) and amount of ressources. This talk will provide a description of the work done at CSCS in collaboration with EPFL to port the MSPAI library on future high performance clusters and its integration in the Trilinos framework.
InvasIC Seminar, September 14, 2011 at FAU: Learning to see and understand
PD Dr. Rolf Würtz (Institut für Neuroinformatik, Ruhr-Universität Bochum)
 Sensor interpretation is one of the central requirements for computing systems to interact sensibly with
their environment. Moreover, the translation of sensor data into semantically meaningful representations
is necessary to exploit the types of computation at which machines are much better than humans.
The most important among the sensory modalities is visual processing. In this talk I will review
self-organizing methods we have developed for the recognition of human faces, human bodies, and
general objects, their performance and shortcomings. Beyond organic learning of new object classes,
representation of all possible visual experiences is somehow required. Human vision seems to be mainly
driven by the vast amount of memorized visual experiences. I will describe some new attempts to
efficiently store and retrieve these experiences, which are currently work in progress.
Sensor interpretation is one of the central requirements for computing systems to interact sensibly with
their environment. Moreover, the translation of sensor data into semantically meaningful representations
is necessary to exploit the types of computation at which machines are much better than humans.
The most important among the sensory modalities is visual processing. In this talk I will review
self-organizing methods we have developed for the recognition of human faces, human bodies, and
general objects, their performance and shortcomings. Beyond organic learning of new object classes,
representation of all possible visual experiences is somehow required. Human vision seems to be mainly
driven by the vast amount of memorized visual experiences. I will describe some new attempts to
efficiently store and retrieve these experiences, which are currently work in progress.
InvasIC-Seminar, August 26, 2011 at FAU:
Physics-inspired Management of Complex Adaptive Network Structures
Dr. Ingo Scholtes (Lehrstuhl für Systemsoftware und Verteilte Systeme, Universität Trier)
Abstract: In this talk a physics-inspired approach towards the management of self-organizing and self-adaptive network topologies will be discussed. It is based on the idea that network infrastructures like the Internet or our biggest Peer-to-Peer systems are becoming so large that it appears justified to design them along models and abstractions originally developed for the study of many-particle systems in statistical physics. Apart from a basic introduction into the statistical mechanics perspective on network structures, distributed topology management schemes will be presented that take advantage of the recently uncovered analogies between random graph theory and statistical physics. They can be used to actively trigger and utilize phase transition and crystallization phenomena as known from physics and thus constitute the basis for what may be called a thermodynamic management of complex, adaptive network structures.
InvasIC Seminar, July 19, 2011 at KIT: What does it take to write efficient proximity algorithms (for robotics, graphics and CAD)
Prof. Kim Young (Ewha Womans University)
Proximity query is a process to reason and derive a geometric relationship among, often time-dependent, objects in space. Typical proximity queries include - continuous and discrete collision detection, Euclidean distance computation, Hausdorff distance computation, penetration depth computation, etc. These queries play a vital role in diverse applications such as non-smooth contact dynamics, robot motion planning, physically-based animation and CAD disassembly planning. In this talk, we will focus on our recent research efforts to devise fast - mostly real-time - and efficient proximity algorithms with different objectives using rather simple approaches, thereby working extremely well in practice. Moreover, we also discuss how we can parallelize these calculations utilizing modern hardware platforms such as multi-core CPUs and GPUs. Finally, we demonstrate how to apply these queries to the aforementioned applications, particularly for robot motion planning and contact dynamics.
InvasIC Seminar, July 11, 2011 at FAU: Profile-Directed Semi-Automatic Parallelisation
Prof. Dr. Bjoern Franke (Institute for Computing Systems Architecture, University of Edinburgh)
 Compiler-based auto-parallelisation is a much studied area, yet has still not found wide-spread
application. This is largely due to the poor exploitation of application parallelism, subsequently
resulting in performance levels far below those which a skilled expert programmer could achieve.
We have identified three weaknesses in traditional parallelising compilers and propose a novel,
integrated approach, resulting in significant performance improvements of the generated parallel code.
First, using profile-driven parallelism detection we overcome the limitations of static analysis,
enabling us to identify more application parallelism and only rely on the user for final approval.
Second, we replace the traditional target-specific and inflexible mapping heuristics with a
machine-learning based prediction mechanism, resulting in better mapping decisions while providing more
scope for adaptation to different target architectures. Third, we target coarse-grained parallelism
in the shape of execution pipelines. Our approach is orthogonal to existing automatic parallelisation
approaches and additional data parallelism may be exploited in the individual pipeline stages.
Compiler-based auto-parallelisation is a much studied area, yet has still not found wide-spread
application. This is largely due to the poor exploitation of application parallelism, subsequently
resulting in performance levels far below those which a skilled expert programmer could achieve.
We have identified three weaknesses in traditional parallelising compilers and propose a novel,
integrated approach, resulting in significant performance improvements of the generated parallel code.
First, using profile-driven parallelism detection we overcome the limitations of static analysis,
enabling us to identify more application parallelism and only rely on the user for final approval.
Second, we replace the traditional target-specific and inflexible mapping heuristics with a
machine-learning based prediction mechanism, resulting in better mapping decisions while providing more
scope for adaptation to different target architectures. Third, we target coarse-grained parallelism
in the shape of execution pipelines. Our approach is orthogonal to existing automatic parallelisation
approaches and additional data parallelism may be exploited in the individual pipeline stages.
- Handout (PDF-Slides)
InvasIC Seminar, July 6, 2011 at FAU: Reconfigurable Computing Research at University of Queensland
Prof. Dr. Neil Bergmann ( Chair in Embedded Systems, University of Queensland)


This talk describes some of the current research projects at University of Queensland in the area of reconfigurable computing and FPGAs. The talk concentrates on three PhD projects which are nearing completion. The HW/SW task migration project looks at network-on-chip topologies and system software that allows running tasks to migrate between hardware and software, in order to make optimum use of the available FPGA resources. The HW/SW Cryto Framework project looks at an architecture which provides a uniform programming interface to the use of hardware accelerators for software routines. The Open Crypto Framework in Linux is used to provide a uniform interface to cryptography functions, independent of which accelerators are present (or not). It also provides load balancing for multiple accelerators. A slot-based hardware accelerator framework is also part of the research. The HW scheduling and context-switching project looks at architectures which provide hardware acceleration of dynamic scheduling and context switching for multi-processing embedded systems implemented on FPGAs. The Open Source Leon SPARC-compatible core, and the eCOS operating system are used to provide the basic computing framework.
- Handout (PDF-Slides)
InvasIC Seminar, April 15, 2011 at FAU: Modellgetriebene Entwicklung vernetzter Systeme mit SDL-MDD
Prof. Dr. Reinhard Gotzhein (TU Kaiserslautern)

InvasIC Seminar, March 30, 2011 at FAU: Das Polyedermodell vor dem Durchbruch?
Dr. Armin Größlinger (Lehrstuhl für Informatik mit Schwerpunkt Programmierung, Universität Passau)
 Das Polyedermodell ist ein mathematisches Modell für die Beschreibung von
verschachtelten Schleifen, deren Schleifenköpfe und Rümpfe bestimmte
Eigenschaften erfüllen: die Iterationsr?auml;ume sind begrenzt durch affin-lineare
Ausdrücke und die Anweisungen in den Rümpfen benutzen Arrays mit affin-linearen
Zugriffsfunktionen als einzige Datenstruktur. In Programmcodes dieser Art, die
im wissenschaftlichen Rechnen, der Bildverarbeitung und anderen Bereichen
häufig auftreten, ist eine automatische Analyse der Datenabhängigkeiten und
eine optimierende Suche nach Transformationen, die z.B. Parallelität oder
Cache-Effizienz in das Programm einführen, möglich. Nach einer kurzen
Einführung in das Polyedermodell gibt der Vortrag einen Überblick über die
aktuellen Möglichkeiten und Probleme des Ansatzes aus praktischer Sicht, z.B.
das Aufbrechen einiger Restriktionen des Modells, Parallelisierung für GPUs und
die Integration des Modells in GCC und LLVM. Abschließend wird auf die in
Passau geplanten Aktivitäten zur Verknüpfung des Polyedermodells mit Techniken
der Just-in-time-Kompilation eingegangen.
Das Polyedermodell ist ein mathematisches Modell für die Beschreibung von
verschachtelten Schleifen, deren Schleifenköpfe und Rümpfe bestimmte
Eigenschaften erfüllen: die Iterationsr?auml;ume sind begrenzt durch affin-lineare
Ausdrücke und die Anweisungen in den Rümpfen benutzen Arrays mit affin-linearen
Zugriffsfunktionen als einzige Datenstruktur. In Programmcodes dieser Art, die
im wissenschaftlichen Rechnen, der Bildverarbeitung und anderen Bereichen
häufig auftreten, ist eine automatische Analyse der Datenabhängigkeiten und
eine optimierende Suche nach Transformationen, die z.B. Parallelität oder
Cache-Effizienz in das Programm einführen, möglich. Nach einer kurzen
Einführung in das Polyedermodell gibt der Vortrag einen Überblick über die
aktuellen Möglichkeiten und Probleme des Ansatzes aus praktischer Sicht, z.B.
das Aufbrechen einiger Restriktionen des Modells, Parallelisierung für GPUs und
die Integration des Modells in GCC und LLVM. Abschließend wird auf die in
Passau geplanten Aktivitäten zur Verknüpfung des Polyedermodells mit Techniken
der Just-in-time-Kompilation eingegangen.
- Handout (PDF-Slides)
- Video High Quality (MP4, 640*480px, 105.5MB)
- Video Low Quality (MP4, 320*240px, 68.7MB)
InvasIC Seminar, March 30, 2011 at TUM: Insieme - an optimization system for OpenMP, MPI and OpenCL programs
Dr. Hans Moritsch (Universität Innsbruck)
Exploiting the capabilities of multicore architectures in specifically optimized applications is a major requirement today. The Insieme source-to-source compilation system targets the automatic optimization of parallel programs implemented with MPI, OpenMP, de facto standards for distributed and shared memory systems, and the OpenCL framework for heterogeneous platforms, including GPUs. Performance improvements of parallel programs can be achieved through program transformations at compile time and/or determining "good" values for tuning parameters of application programs and libraries at runtime. Exploiting the diversity and heterogeneity of multicore architecture often creates intractably complex optimization problems. The statistical machine learning approach empirically explores the optimization space and learns a relationship between optimizations and the corresponding performance outcome. A trained machine can map code regions of arbitrary new programs, based on their properties, onto the optimiziation space and find profitable transformation sequences and parameters values. The talk also presents the architecture and implementation status of the Insieme system.
- Handout can be found here
InvasIC Seminar, March 3, 2011 at FAU: Das Polyedermodell zur automatischen Schleifenparallelisierung.
Prof. Dr. Christian Lengauer (Lehrstuhl für Informatik mit Schwerpunkt Programmierung, Universität Passau)

Der Vortrag gibt einen Überblick über die Entwicklung eines semantischen Modells zur automatischen Parallelisierung von Schleifenprogrammen. In diesem Modell sind die Schritte eines Satzes von n verschachtelten Schleifen als Punkte in einem n-dimensionalen Polyeder repräsentiert. Das Modell eignet sich zur automatischen Suche der besten Lösung nach einer vorgegebenen Zielfunktion. Typische Zielfunktionen sind die Minimalzahl auszuführender paralleler Schritten bei Nutzung möglichst weniger Prozessoren oder bei maximalem Durchsatz. Nach der Einführung des "klassischen" Basismodells werden eine Reihe von Erweiterungen skizziert, die in den letzten zwei Jahrzehnten vorgenommen wurden. Den Abschluss bildet ein kurzer Ausblick auf die Rolle des Modells in der zukünftigen Welt der Multicores und Manycores.
- Handout (PDF-Slides)
InvasIC Seminar, February 18, 2011 at FAU: Adaptive Verbindungsnetzwerke für Parallelrechner: vom SAN (System Area Network) zum NoC (Network on Chip)
Prof. Dr. Erik Maehle (Institut für Technische Informatik, Universität zu Lübeck)
 Verbindungsnetzwerke stellen die Kommunikationsverbindungen zwischen den Rechenknoten
eines Parallelrechnersystems zur Verfügung und bestimmen damit ganz wesentlich
dessen Eigenschaften mit. Traditionell werden sie als System Area Network (SAN)
mittels eigener Netzwerkadapter und Router realisiert. Mit dem Aufkommen von Multi- und Many-Core-Architekturen
stellen chipinterne Realisierungen als NoC (Network on Chip) derzeit einen wichtigen Forschungsgegenstand dar.
Ein wichtiger Aspekt ist dabei Adaptivität an unterschiedliche Verkehrsmuster oder Fehlersituationen.
Der Vortrag führt zunächst anhand einer regelbasierten Darstellung in adaptive Routing-Algorithmen sowie
deren Analyse durch Simulationen mit RubinLab und deren Implementierung in SANs mittels eines regelbasierten Routers ein.
Adaptivität bei NoCs wird anhand der Beispiele des topologieadaptiven, dynamisch rekonfigurierbaren Netzwerks CoNoChi
sowie einer modularen NoC-Architektur für die Priorisierung semi-statischer Datenströme behandelt.
Verbindungsnetzwerke stellen die Kommunikationsverbindungen zwischen den Rechenknoten
eines Parallelrechnersystems zur Verfügung und bestimmen damit ganz wesentlich
dessen Eigenschaften mit. Traditionell werden sie als System Area Network (SAN)
mittels eigener Netzwerkadapter und Router realisiert. Mit dem Aufkommen von Multi- und Many-Core-Architekturen
stellen chipinterne Realisierungen als NoC (Network on Chip) derzeit einen wichtigen Forschungsgegenstand dar.
Ein wichtiger Aspekt ist dabei Adaptivität an unterschiedliche Verkehrsmuster oder Fehlersituationen.
Der Vortrag führt zunächst anhand einer regelbasierten Darstellung in adaptive Routing-Algorithmen sowie
deren Analyse durch Simulationen mit RubinLab und deren Implementierung in SANs mittels eines regelbasierten Routers ein.
Adaptivität bei NoCs wird anhand der Beispiele des topologieadaptiven, dynamisch rekonfigurierbaren Netzwerks CoNoChi
sowie einer modularen NoC-Architektur für die Priorisierung semi-statischer Datenströme behandelt.
- Handout (PDF_Slides)
- Video High Quality (MP4, 640*480px, 91.6MB)
- Video Low Quality (MP4, 320*240px, 60.9MB)
InvasIC Seminar, January 31, 2011 at FAU: Wie zuverlässig sind robuste Systeme wirklich?
Prof. Dr. Sybille Hellebrand (Institut für Elektrotechnik und Informationstechnik, Universität Paderborn)
 Fertigungstechnologien im Nanometerbereich ermöglichen
es mittlerweile hochkomplexe Systeme in ein einziges
Chip oder in 3-dimensionale Chipstapel zu integrieren.
Probleme bereiten dabei allerdings zunehmende
Schwankungen der Schaltungsparameter und die wachsende
Empfindlichkeit gegenüber äusseren Störeinflüssen.
Durch einen robusten Entwurf soll trotzdem eine
hohe Produktqualität und ein zuverlässiger Systembetrieb
gewährleistet werden. Beispiele reichen hier von
klassischen fehlertoleranten Architekturen bis hin zu
neuen selbstkalibrierenden Ansätzen.
Aber gerade ein robuster Entwurf stellt erhöhte Anforderungen
an die Qualitätssicherung. So müssen zum
Beispiel bei der Entwurfsvalidierung nicht nur die korrekte
Funktion sondern auch Robustheitseigenschaften
nachgewiesen werden. Beim Produktionstest genügt es
einerseits nicht mehr zu zeigen, dass ein System funktionsfähig
ist, sondern die verbleibende Zuverlässigkeit
muss analysiert werden (Quality Binning). Andererseits
sollen Ausbeuteverluste durch Aussortieren von Systemen
mit kompensierbaren Fehlern vermieden werden.
Der Vortrag verdeutlicht die genannten Probleme anhand
einiger typischer Architekturen und zeigt erste Lösungsansätze
dafür auf.
Fertigungstechnologien im Nanometerbereich ermöglichen
es mittlerweile hochkomplexe Systeme in ein einziges
Chip oder in 3-dimensionale Chipstapel zu integrieren.
Probleme bereiten dabei allerdings zunehmende
Schwankungen der Schaltungsparameter und die wachsende
Empfindlichkeit gegenüber äusseren Störeinflüssen.
Durch einen robusten Entwurf soll trotzdem eine
hohe Produktqualität und ein zuverlässiger Systembetrieb
gewährleistet werden. Beispiele reichen hier von
klassischen fehlertoleranten Architekturen bis hin zu
neuen selbstkalibrierenden Ansätzen.
Aber gerade ein robuster Entwurf stellt erhöhte Anforderungen
an die Qualitätssicherung. So müssen zum
Beispiel bei der Entwurfsvalidierung nicht nur die korrekte
Funktion sondern auch Robustheitseigenschaften
nachgewiesen werden. Beim Produktionstest genügt es
einerseits nicht mehr zu zeigen, dass ein System funktionsfähig
ist, sondern die verbleibende Zuverlässigkeit
muss analysiert werden (Quality Binning). Andererseits
sollen Ausbeuteverluste durch Aussortieren von Systemen
mit kompensierbaren Fehlern vermieden werden.
Der Vortrag verdeutlicht die genannten Probleme anhand
einiger typischer Architekturen und zeigt erste Lösungsansätze
dafür auf.
- Handout (PDF-Slides)
- Video High Quality (MP4, 640*480px, 105.5MB)
- Video Low Quality (MP4, 320*240px, 68.7MB)
Events 2010
InvasIC Seminar, November 26, 2010 at FAU: System-level MPSoC Design with Daedalus
Hristo Nikolov, Ph.D. (Leiden Institute of Advanced Computer Science (LIACS))
The Daedalus framework uses the polyhedral process network (PPN) model of computation to program and to map streaming media applications onto Multi-Processor Systems on Chip (MPSoC) platforms. PPNs are automatically derived from sequential nested-loop programs by using the PNGen compiler. In the PNGen partitioning strategy, a process is created for each function call statement in the nested loop program. As a result, the number of processes in the PPN is equal to the number of function call statements in the nested loop program. This partitioning strategy may not necessarily result in a PPN that meets the performance or resource requirements. To meet these requirements, a designer can apply algorithmic transformations to increase parallelism by splitting processes or to decrease parallelism by merging processes into a single component. In order to achieve best results, it is necessary to use both transformations in combination. However, the transformations can be applied in many different ways, on different processes, and in different order which can result in significant differences in performance. In this talk, I will present the transformations and the metric we use in order to evaluate the "quality" of a transformation. Also, I will present our holistic approach of combining the process splitting and merging transformations in a way that it relieves the designer from the difficult task to select the processes on which the transformations to be applied. More details and publication lists can be found on the Daedalus website
InvasIC Seminar, November 23, 2010 at TUM: Optimising for a multi-core when you have to share
Prof. Michael O'Boyle (School of Informatics, University of Edinburgh)
Much compiler-orientated work in the area of mapping parallel programs has ignored the issue of external workload. Given that the majority of platforms will not be dedicated to just one task at a time, the impact of other jobs needs to be addressed. As mapping is highly dependent on the underlying machine, a technique that is easily portable across platforms is desirable. In this talk I will present a machine-learning based approach for predicting the optimal number of threads for a given data-parallel application in the presence of external workload. This results in a significant speedup over the default OpenMP approach. I will then discuss current work in developing more cooperative approach to mapping for different system objectives.
InvasIC Seminar, November 3, 2010 at FAU: Designs and design methods for embedded security
Prof. Ingrid Verbauwhede (K.U. Leuven)
In this presentation, the focus will be on the implementation aspects of
cryptographic and security applications for embedded devices. Over the
years, mathematically strong cryptographic algorithms and protocols have
been created. The weak link has become the incorporation of these algorithms
in small, embedded, power constrained devices. It requires both an efficient
and a secure implementation. Security and efficiency need to be considered
at each design step from protocols, algorithms and architectures down to
circuits. In this presentation, we will first give an overview of the COSIC
research group at the K.U.Leuven. Then we will discuss the security pyramid,
i.e. a systematic design method for designing secure embedded devices. We
will give examples of secure secret key and public key implementations and
will illustrate this with diverse applications such as RFID, biometric or
privacy-by-design applications.
More details and publication lists can be found on the
COSIC website